Tre paradigmer for at forankre AI-agenter i private data — og hvorfor ”brug RAG” ikke længere er et fuldstændigt svar.
Spørgsmålet alle teams før eller siden stiller
Hvordan skal en AI-agent få adgang til jeres private data?
I to år var standardsvaret ”brug RAG.” Opdel dokumenter, indlejr dem, hent de bedste match ved forespørgselstid, indsæt dem i prompten. Det virker til engangsspørgsmål over statiske dokumenter og er stadig et fornuftigt udgangspunkt for prototyper.
Det er ikke et fuldstændigt svar til produktionsagenter.
Den virkelige beslutning er ikke RAG eller ikke-RAG. Det er et valg mellem tre paradigmer — hver passer til en anden type arbejde. Det forkerte valg betyder, at I betaler for kapacitet, I ikke behøver, eller beder et værktøj om at løse et problem, det ikke er bygget til.
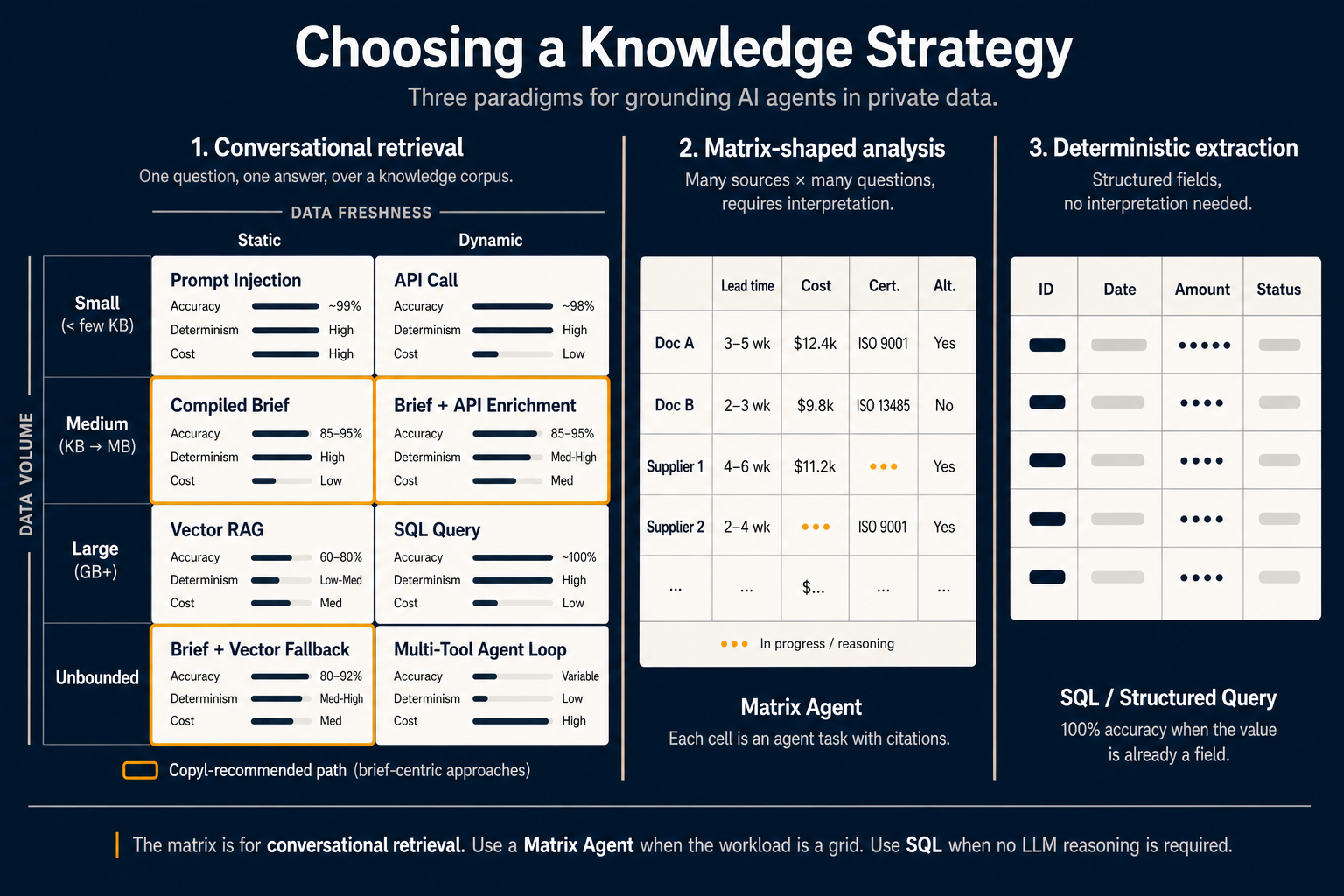
Kortet ovenfor viser alle tre.
Paradigme 1 — Samtalehentning
Det er det velkendte: ét spørgsmål, ét svar, forankret i et vidensgrundlag. De fleste chatbaserede agenter lever her.
Men det ”rigtige” hentningsvalg afhænger af to variable, de færreste teams gør eksplicitte: hvor meget data der er, og hvor ofte data ændrer sig.
Plot de to akser — og otte celler vises:
Lille volumen, statiske data — Prompt-injektion. Når relevant data passer i modellens kontekstvindue og ikke ændrer sig midt i sessionen, er det simpleste svar at inkludere det hele. Nøjagtigheden nærmer sig 99 %, fordi modellen ikke gætter — den ser alt. Prisen: I betaler tokens ved hver forespørgsel. Fint til korte specifikationer, dyrt til alt andet.
Lille volumen, dynamiske data — API-kald. Aktuel aktiekurs, antal åbne sager, brugerens seneste login. Dataene er små nok til prompten, men skal være friske. Et direkte API- eller funktionskald er den rigtige primitive. Ingen retrieval-arkitektur nødvendig.
Mellem volumen, statiske data — Kompileret brief. Her har samtalen flyttet sig i 2026. I stedet for at fortolke de samme dokumenter ved hver forespørgsel fortolker I én gang ved kompileringstid og gemmer resultatet som en opgaveoptimeret artefakt. Agenten læser briefet, ikke rådokumenterne. Nøjagtighed 85–95 %, høj determinisme, lavere omkostning pr. forespørgsel, fordi I sender destillerede resuméer i stedet for rå chunks.
Mellem volumen, dynamiske data — Brief + API-berigelse. Samme kompilerede tilgang med et live API ovenpå, der injicerer aktuelle værdier i den i øvrigt forfortolkede kontekst. Passer til fx ”forklar vores returpolitik og sig, hvor mange returer vi har behandlet i dag.”
Stor volumen, statiske data — Vektor-RAG. Klassikeren. Når I har gigabyte af statiske dokumenter og ikke kan kompilere det hele, falder I tilbage på vektorhentning. Nøjagtighed typisk 60–80 %, determinisme lav til middel (samme spørgsmål kan give forskellige chunks mellem kørsler), og I fortolker rå tekst ved forespørgselstid igen. Nyttigt — men ikke standard for de fleste agentopgaver længere.
Stor volumen, dynamiske data — SQL-forespørgsel. Når dataene er store og dynamiske, men ligger struktureret i en database: skriv forespørgslen. Indlejr ikke transaktionsposter. SQL giver 100 % nøjagtighed — intet fortolkningstrin, svaret er feltet.
Ubegrænset, statisk — Brief + vektor-fallback. Når korpus er større end det, I fornuftigt kan kompilere fuldt ud: kompilér højtrafikkerede kerner til briefs og lad vektorhentning tage langhalen. Nøjagtighed 80–92 %. Sweet spot for de fleste produktionsassistenter.
Ubegrænset, dynamisk — Multi-værktøjs-agent-loop. Det sværeste tilfælde: for stort til fuld kompilering, for varieret til direkte forespørgsel, for hurtigt til cache. Agenten skal planlægge, kalde flere værktøjer, evaluere mellemresultater og gentage. Variabel nøjagtighed, lav determinisme, høj omkostning. Kun når intet simplere rækker.
De orange-indrammede celler markerer brief-centrerede stien — celler der flytter ræsonnement fra forespørgselstid til kompileringstid. Det er den konfiguration vi anbefaler som standard for samtaleagenter i produktion i Copyl.
Paradigme 2 — Matrixformet analyse
2×4-matricen besvarer ét spørgsmål godt. Den er det forkerte værktøj til et andet, der opstår lige så ofte: ”analysér 200 dokumenter mod 15 dimensioner og giv mig en struktureret sammenligning.”
Det er ikke samtalehentning. Det er en anden arbejdsform.
En BOM-analytiker der sammenligner leverandørtilbud, et M&A-team med 50 kontrakter og 20 risikodimensioner, en CFO med budgetter på tværs af 12 datterselskaber — matrixformede flows. Rækker er kilder. Kolonner er spørgsmål. Cellerne er skæringspunktet: hver celle er en lille agentopgave der udtrækker og ræsonnerer om den kilde mod det spørgsmål — med citationer.
Det er hvad en Matrix Agent gør. Brugerfladen er et regneark frem for chat. Brugeren tilføjer rækker ved at pege på kilder (dokumenter, leverandører, datterselskaber, KB-artikler, API-poster) og kolonner med en kort prompt for hvad cellen skal udtrække eller vurdere. Agenten udfylder gitteret parallelt med egen konfidens og citationer pr. celle.
Midterkolonnen i diagrammet viser praksis: dokumenter og leverandører som rækker; leveringstid, omkostning, certificering og alternativer som kolonner; nogle celler udfyldt, andre stadig i gang. ”I gang” i to celler er meningsfuldt — Matrix Agents er eksplicit per-celle, så én langsom eller fejlende celle blokerer ikke resten af gitteret.
Har I nogensinde bygget et engangsregneark for at sammenligne udtræk fra mange dokumenter, har I gjort i hånden hvad en Matrix Agent gør i skala.
Paradigme 3 — Deterministisk ekstraktion
Det tredje paradigme er det mest undervurderede og det nemmeste at glemme når AI er på mode: brug slet ikke en LLM.
Hvis værdien allerede findes som felt i en database, i et struktureret API-svar, i en CSV eller i velformet JSON — behøver I hverken retrieval, brief eller Matrix Agent. I behøver et SELECT.
Deterministisk ekstraktion giver 100 % nøjagtighed, perfekt reproducerbarhed og næsten nul omkostning pr. forespørgsel. I eskalerer til LLM først når data ikke allerede er strukturerede, eller spørgsmålet ikke kan besvares ved at kombinere strukturerede felter med simpel logik.
Overraskende meget af det der bygges som ”AI-funktioner” burde være SQL.
Sådan vælger I — kort version
Sidefoden i diagrammet siger det på én linje — her uddybet:
- Samtalehentning (Paradigme 1) når brugeren stiller et spørgsmål og forventer svar i løbende tekst, forankret i jeres private corpus.
- Matrix Agent (Paradigme 2) når arbejdsbyrden er et gitter: mange kilder mod mange dimensioner og brugeren vil have struktureret sammenligning frem for samtale.
- SQL eller struktureret forespørgsel (Paradigme 3) når værdien allerede er et felt. Ingen fortolkning nødvendig, ingen LLM nødvendig.
De dyre fejl sker når teams tvinger ét paradigme til at udføre et andets job. Samtalehentning kæmper med gitteranalyse — brugeren kører 200 separate forespørgsler i hånden. Matrix Agents er overkill til ”hvad er vores returpolitik” — det er bare et brief. At bede en LLM om at udtrække en værdi der allerede er en kolonne er at betale for fortolkning der ikke krævedes.
Hvor det efterlader ”RAG eller ikke”-debatten
Vektor-RAG er én celle på kortet, ikke hele kortet. Det er det rigtige værktøj til ét problem: store mængder statisk ustruktureret data hvor I ikke kan kompilere hele korpus og spørgsmålet er samtalebaseret.
Til alt andet findes der et bedre match. De teams der leverer produktionsagenter gennem 2026 er dem der stopper med at behandle RAG som standard og matcher paradigme med arbejdsbyrde.
Det er målestokken. Diagrammet gør valget synligt.
Hvor Copyl passer ind
I Copyl findes alle tre paradigmer som indbyggede primitive:
- Samtalehentning kører på Knowledge Briefs kompileret fra KB (Books, Chapters, Docs) med vektor-fallback til langhale-spørgsmål.
- Matrix Agents er førsteklasses agenter (samme User-and-properties-mønster som samtaleagenter) over et 2D-gitter af kilder × analysedimensioner.
- Deterministisk ekstraktion understøttes via IntegrationApps og direkte SQL/API-adgang; resultater kan bruges i de andre paradigmer når fortolkning behøves nedstrøms.
Fordi alle tre lever på samme platform gælder samme Agent Profile, Policies og SOPs på tværs — en agent der laver samtale-Q&A mandag og matrixanalyse tirsdag bruger samme compliance-konfiguration, samme revisionsspor og samme tenant-isolation.
Diagrammet ovenfor er kortet. Platformen er det der lader jer flytte mellem celler uden at genbygge fra bunden.