Drie paradigma’s voor het verankeren van AI-agenten in privédata — en waarom “gebruik RAG” geen volledig antwoord meer is.
De vraag die elk team uiteindelijk stelt
Hoe moet een AI-agent bij uw privédata?
Twee jaar lang was het standaardantwoord “gebruik RAG.” Documenten opdelen, embedden, de beste matches op querytijd ophalen, in de prompt plakken. Het werkt voor eenmalige vragen over statische documenten en blijft een redelijk uitgangspunt voor prototypes.
Het is geen volledig antwoord voor productie-agenten.
De echte keuze is niet RAG of geen RAG. Het is een keuze tussen drie paradigma’s — elk past bij een andere vorm van werk. Verkeerd kiezen betalen voor mogelijkheden die u niet nodig heeft, of een tool vragen een probleem op te lossen waarvoor die niet is gebouwd.
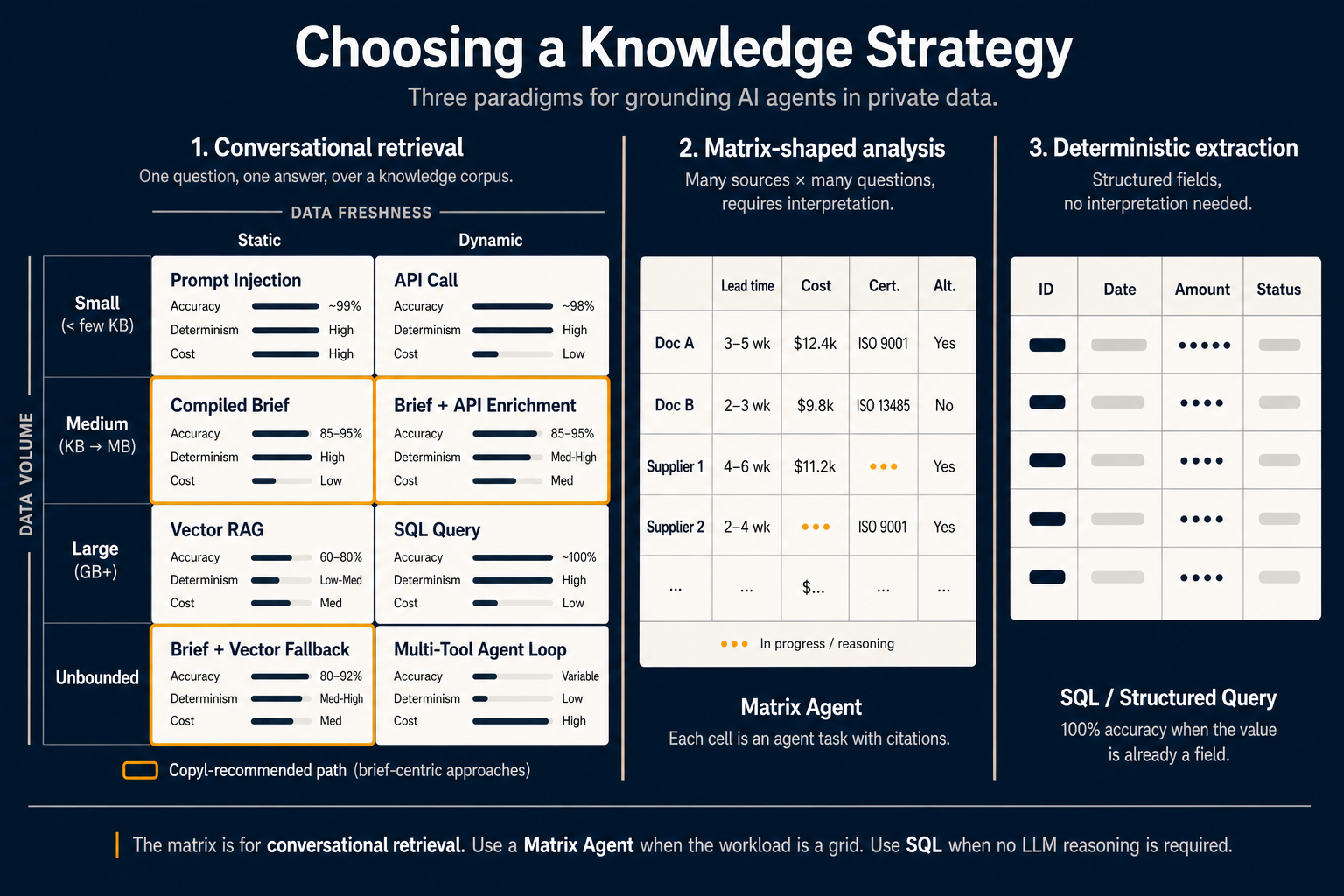
De kaart hierboven toont alle drie.
Paradigma 1 — Conversationele retrieval
Dit is het bekende patroon: één vraag, één antwoord, verankerd in een kenniscorpus. De meeste chatagents leven hier.
Maar de “juiste” retrievalmethode hangt af van twee variabelen die teams zelden expliciet maken: hoeveel data er is, en hoe vaak die verandert.
Teken die twee assen — en er verschijnen acht cellen:
Klein volume, statische data — Prompt-injectie. Past de relevante data in het contextvenster van het model en verandert die niet tijdens de sessie, dan is de eenvoudigste optie alles meesturen. De nauwkeurigheid nadert 99 % omdat het model niet hoeft te raden — het ziet alles. De prijs: u betaalt die tokens bij elke query. Prima voor korte specs, duur voor de rest.
Klein volume, dynamische data — API-aanroep. Actuele koers, aantal open tickets, laatste login. De data is klein genoeg voor de prompt maar moet vers zijn. Een directe API- of functieaanroep is het juiste primitive. Geen retrieval-architectuur nodig.
Middel volume, statische data — Gecompileerde brief. Hier is het gesprek in 2026 verschoven. In plaats van dezelfde documenten bij elke query opnieuw te interpreteren, interpreteert u ze eenmaal compileertijd en slaat u het resultaat op als taakgeoptimaliseerd artefact. De agent leest de brief, niet de ruwe documenten. Nauwkeurigheid 85–95 %, hoge determinisme, lagere kosten per query omdat u gedistilleerde samenvattingen stuurt in plaats van ruwe chunks.
Middel volume, dynamische data — Brief + API-verrijking. Dezelfde gecompileerde aanpak met een live API erbovenop die actuele waarden in de vooraf geïnterpreteerde context injecteert. Geschikt voor “leg ons retourbeleid uit en zeg hoeveel retouren we vandaag hebben afgehandeld.”
Groot volume, statische data — Vector-RAG. De klassieker. Gigabytes aan statische documenten die u niet volledig kunt compileren: val terug op vectorretrieval. Nauwkeurigheid typisch 60–80 %, determinisme laag tot middel (dezelfde query kan verschillende chunks geven) en u interpreteert weer ruwe tekst op querytijd. Nuttig, maar niet langer de standaard voor de meeste agentwerk.
Groot volume, dynamische data — SQL-query. Data is groot en dynamisch maar staat in een gestructureerde database: schrijf de query. Gebruik geen transactionele records embedden. SQL geeft 100 % nauwkeurigheid — geen interpretatiestap; het antwoord is het veld.
Onbegrensd, statisch — Brief + vectorfallback. Corpus groter dan wat u volledig wilt compileren: compileer het kernverkeer naar briefs en laat vectorretrieval de lange staart afhandelen. Nauwkeurigheid 80–92 %. Sweet spot voor de meeste productie-assistenten.
Onbegrensd, dynamisch — Multi-tool-agentlus. Het zwaarste geval: te groot om te compileren, te gevarieerd om direct te bevragen, te snel veranderend om te cachen. De agent moet plannen, meerdere tools aanroepen, tussenresultaten evalueren en itereren. Variabele nauwkeurigheid, laag determinisme, hoge kosten. Alleen als niets eenvoudigers volstaat.
De oranje omrande cellen markeren het brief-centrale pad — cellen die redenering van querytijd naar compileertijd verplaatsen. Dat is de configuratie die we standaanbevelen voor conversationele productie-agents in Copyl.
Paradigma 2 — Matrixvormige analyse
De 2×4-matrix beantwoordt één vraag goed. Het is het verkeerde gereedschap voor een andere die net zo vaak komt: “analyseer 200 documenten tegen 15 dimensies en geef een gestructureerde vergelijking.”
Dat is geen conversationele retrieval. Het is een andere werksoort.
Een BOM-analist die leveranciersaanbiedingen vergelijkt, een M&A-team met 50 contracten en 20 risicodimensies, een CFO met budgetten over 12 dochterondernemingen — matrixvormige workflows. Rijen zijn bronnen. Kolommen zijn vragen. Cellen zijn de doorsnede: elke cel is een kleine agenttaak die die bron tegen die vraag extraheert en redeneert, met citaten.
Dat doet een Matrix Agent. De interface is een spreadsheet, geen chat. De gebruiker voegt rijen toe door naar bronnen te wijzen (documenten, leveranciers, dochterondernemingen, KB-artikelen, API-records) en kolommen met een korte prompt die bepaalt wat elke cel moet extraheren of evalueren. De agent vult het raster parallel; elke cel heeft eigen betrouwbaarheid en citaten.
De middelste kolom in het diagram toont de praktijk: documenten en leveranciers als rijen; levertijd, kosten, certificering en alternatieven als kolommen; sommige cellen ingevuld, andere nog bezig. “Bezig” in twee cellen is betekenisvol — Matrix Agents zijn expliciet per cel; één trage of falende cel blokkeert niet het hele raster.
Heeft u ooit een eenmalig spreadsheet gebouwd om geëxtraheerde gegevens uit veel documenten te vergelijken, dan deed u met de hand wat een Matrix Agent op schaal doet.
Paradigma 3 — Deterministische extractie
Het derde paradigma is het minst gevierde en het makkelijkste te vergeten als AI overal is: gebruik helemaal geen LLM.
Als de waarde die u wilt al een veld in een database is, in een gestructureerd API-antwoord, in een CSV of in goed gevormde JSON — u heeft geen retrieval, geen brief en geen Matrix Agent nodig. U heeft een SELECT nodig.
Deterministische extractie geeft 100 % nauwkeurigheid, perfecte reproduceerbaarheid en vrijwel geen kosten per query. U schaalt alleen naar een LLM-aanpak als de data niet gestructureerd is of de vraag niet kan worden beantwoord door gestructureerde velden met eenvoudige logica te combineren.
Verrassend veel van wat als “AI-functies” wordt gebouwd, zou SQL moeten zijn.
Hoe kiezen — korte versie
De voettekst van het diagram zegt het op één regel — hier uitgeschreven:
- Conversationele retrieval (Paradigma 1) wanneer de gebruiker een vraag stelt en een antwoord in proza verwacht, verankerd in uw privécorpus.
- Matrix Agent (Paradigma 2) wanneer de workload een raster is: veel bronnen tegen veel dimensies en de gebruiker wil een gestructureerde vergelijking in plaats van een gesprek.
- SQL of gestructureerde query (Paradigma 3) wanneer de waarde al een veld is. Geen interpretatie nodig, geen LLM nodig.
Dure fouten ontstaan wanneer teams één paradigma het werk van een ander laten doen. Conversationele retrieval worstelt met rasteranalyse — de gebruiker draait 200 aparte queries. Matrix Agents zijn overkill voor “wat is ons retourbeleid” — dat is alleen een brief. Een LLM vragen een waarde te extraheren die al een kolom is, betaalt interpretatie die niet nodig was.
Waar het “RAG ja of nee”-debat blijft
Vector-RAG is één cel op de kaart, niet de hele kaart. Het is het juiste gereedschap voor één probleemvorm: grote hoeveelheden statische ongestructureerde data waarbij u het hele corpus niet kunt compileren en de vraag conversationeel is.
Voor alles bestaat er een beter passend hulpmiddel. Teams die in 2026 productie-agents uitrollen, houden op met RAG als standaard en matchen paradigma met workload.
Dat is de lat. Het diagram maakt de keuze zichtbaar.
Waar Copyl past
In Copyl bestaan alle drie de paradigma’s als native primitieven:
- Conversationele retrieval draait op Knowledge Briefs gecompileerd uit de KB (Books, Chapters, Docs), met vectorfallback voor long-tail-vragen.
- Matrix Agents zijn first-class agents (opgeslagen met hetzelfde User-and-properties-patroon als conversationele agents) over een 2D-raster van bronnen × analysedimensies.
- Deterministische extractie wordt ondersteund via IntegrationApps en directe SQL/API-toegang, met resultaten beschikbaar voor de andere paradigma’s wanneer downstream interpretatie nodig is.
Omdat alle drie op hetzelfde platform leven, gelden dezelfde Agent Profile, Policies en SOPs voor alle paradigma’s — een agent die maandag conversationele Q&A doet en dinsdag matrixanalyse gebruikt dezelfde compliance-configuratie, hetzelfde auditspoor en dezelfde tenant-isolatieregels.
Het diagram hierboven is de kaart. Het platform laat u tussen cellen bewegen zonder vanaf nul te herbouwen.