Trois paradigmes pour ancrer les agents IA dans les données privées — et pourquoi « utilisez le RAG » n’est plus une réponse complète.
La question que toute équipe finit par poser
Comment un agent IA doit-il accéder à vos données privées ?
Pendant deux ans, la réponse par défaut était « utilisez le RAG. » Découper les documents, les intégrer, récupérer les meilleures correspondances au moment de la requête, les coller dans le prompt. Cela fonctionne pour des questions ponctuelles sur des documents statiques et reste un point de départ raisonnable pour les prototypes.
Ce n’est pas une réponse complète pour les agents de production.
La vraie décision n’est pas RAG ou pas RAG. C’est un choix entre trois paradigmes — chacun correspond à une forme de travail différente. Choisir la mauvaise option, c’est payer pour des capacités inutiles ou demander à un outil de résoudre un problème pour lequel il n’a pas été conçu.
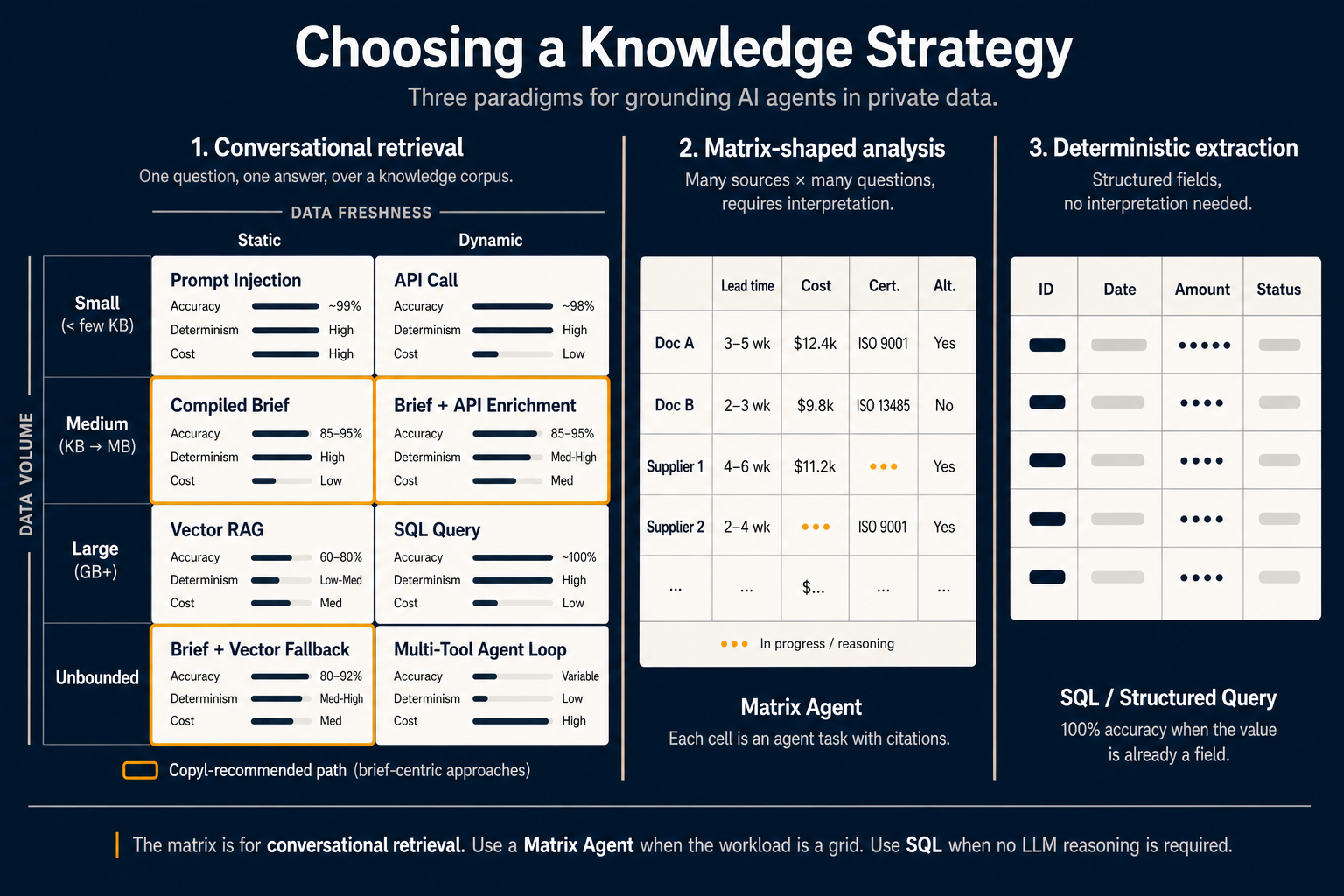
La carte ci-dessus montre les trois.
Paradigme 1 — Récupération conversationnelle
C’est le familier : une question, une réponse, ancrée dans un corpus. La plupart des agents conversationnels vivent ici.
Mais la « bonne » méthode de récupération dépend de deux variables que peu d’équipes explicient : volume des données et fréquence de changement.
Tracez ces deux axes — huit cases apparaissent :
Petit volume, données statiques — Injection dans le prompt. Lorsque les données pertinentes tiennent dans la fenêtre de contexte du modèle et ne changent pas en session, la réponse la plus simple est de tout inclure. La précision approche 99 % car le modèle ne devine pas — il voit tout. Le coût : vous payez ces jetons à chaque requête. Adapté aux courtes spécifications, cher pour le reste.
Petit volume, données dynamiques — Appel API. Cours boursier actuel, nombre de tickets ouverts, dernière connexion. Les données sont assez petites pour le prompt mais doivent être fraîches. Un appel API ou fonction direct est la bonne primitive. Pas besoin d’architecture de récupération.
Volume moyen, données statiques — Brief compilé. C’est là que le débat a bougé en 2026. Au lieu de réinterpréter les mêmes documents à chaque requête, vous les interprétez une fois à la compilation et stockez le résultat comme artefact optimisé pour la tâche. L’agent lit le brief, pas les documents bruts. Précision 85–95 %, déterminisme élevé, coût par requête plus faible grâce à des résumés distillés plutôt qu’à des fragments bruts.
Volume moyen, données dynamiques — Brief + enrichissement API. Même approche compilée, avec un appel API en direct qui injecte les valeurs actuelles dans le contexte déjà préinterprété. Adapté à « expliquez notre politique de retours et dites-moi combien de retours nous avons traités aujourd’hui. »
Grand volume, données statiques — RAG vectoriel. Le classique. Des gigaoctets de documents statiques que vous ne pouvez pas tout compiler : retombez sur la récupération vectorielle. Précision typique 60–80 %, déterminisme faible à moyen (la même requête peut renvoyer des fragments différents), et vous réinterprétez du texte brut au moment de la requête. Utile, mais plus le défaut pour la plupart des charges agent.
Grand volume, données dynamiques — Requête SQL. Données volumineuses et dynamiques mais dans une base structurée : écrivez la requête. N’intégrez pas les enregistrements transactionnels. Le SQL offre 100 % de précision — pas d’étape d’interprétation ; la réponse est le champ.
Illimité, statique — Brief + repli vectoriel. Lorsque le corpus dépasse ce que vous voudriez compiler entièrement, compilez le cœur à fort trafic en briefs et laissez la récupération vectorielle pour la longue traîne. Précision 80–92 %. Le point idéal pour la plupart des assistants knowledge en production.
Illimité, dynamique — Boucle multi-outils. Le cas le plus dur : trop volumineux à compiler, trop varié pour une requête directe, trop rapide pour la mise en cache. L’agent doit planifier, appeler plusieurs outils, évaluer les résultats intermédiaires et itérer. Précision variable, faible déterminisme, coût élevé. Seulement lorsque rien de plus simple ne suffit.
Les cases à bordure orange marquent le chemin centré sur les briefs — celles qui déplacent le raisonnement du temps de requête au temps de compilation. C’est la configuration que nous recommandons par défaut pour les agents conversationnels de production dans Copyl.
Paradigme 2 — Analyse en forme de matrice
La matrice 2×4 répond bien à une question. C’est le mauvais outil pour une autre tout aussi fréquente : « analysez 200 documents selon 15 dimensions et donnez-moi une comparaison structurée. »
Ce n’est pas de la récupération conversationnelle. C’est une autre forme de travail.
Un analyste BOM comparant des offres fournisseurs, une équipe M&A examinant 50 contrats selon 20 dimensions de risque, un CFO passant en revue des budgets sur 12 filiales — des flux en forme de matrice. Les lignes sont des sources. Les colonnes sont des questions. Les cellules sont l’intersection : chaque cellule est une petite tâche d’agent qui extrait et raisonne sur cette source face à cette question, avec citations.
C’est ce que fait un Matrix Agent. L’interface est un tableur, pas un chat. L’utilisateur ajoute des lignes en pointant vers des sources (documents, fournisseurs, filiales, articles KB, enregistrements API) et des colonnes avec un court prompt définissant ce que chaque cellule doit extraire ou évaluer. L’agent remplit la grille en parallèle ; chaque cellule a son propre score de confiance et ses citations.
La colonne centrale du diagramme montre la pratique : documents et fournisseurs en lignes ; délai, coût, certification et alternatives en colonnes ; certaines cellules remplies, d’autres en cours. L’indicateur « en cours » dans deux cellules compte — les Matrix Agents sont explicitement par cellule ; une cellule lente ou en échec ne bloque pas le reste de la grille.
Si vous avez déjà construit un tableur ponctuel pour comparer des données extraites de nombreux documents, vous avez fait à la main ce qu’un Matrix Agent fait à l’échelle.
Paradigme 3 — Extraction déterministe
Le troisième paradigme est le plus sous-estimé et le plus facile à oublier quand l’IA est partout : ne pas utiliser de LLM du tout.
Si la valeur souhaitée est déjà un champ dans une base de données, dans une réponse API structurée, dans un CSV ou dans du JSON bien formé — vous n’avez pas besoin de récupération, ni de brief, ni de Matrix Agent. Vous avez besoin d’un SELECT.
L’extraction déterministe donne 100 % de précision, une reproductibilité parfaite et un coût quasi nul par requête. On ne passe à une approche LLM que si les données ne sont pas structurées ou si la question ne peut pas être résolue en combinant des champs avec une logique simple.
Étonnamment, une grande partie de ce qui est vendu comme « fonctionnalités IA » devrait être du SQL.
Comment choisir — version courte
Le pied du diagramme le résume sur une ligne — voici le détail :
- Récupération conversationnelle (Paradigme 1) lorsque l’utilisateur pose une question et attend une réponse en prose, ancrée dans votre corpus privé.
- Matrix Agent (Paradigme 2) lorsque la charge est une grille : nombreuses sources et dimensions, comparaison structurée plutôt qu’une conversation.
- SQL ou requête structurée (Paradigme 3) lorsque la valeur est déjà un champ. Pas d’interprétation, pas de LLM.
Les erreurs coûteuses surviennent lorsque les équipes forcent un paradigme à faire le travail d’un autre. La récupération conversationnelle peine sur l’analyse en grille — l’utilisateur enchaîne 200 requêtes séparées. Les Matrix Agents sont excessifs pour « quelle est notre politique de retours » — ce n’est qu’un brief. Demander à un LLM d’extraire une valeur qui est déjà une colonne, c’est payer une interprétation inutile.
Où en est le débat « RAG ou pas »
Le RAG vectoriel est une case sur la carte, pas la carte entière. C’est le bon outil pour un type de problème : grands volumes de données statiques non structurées lorsque vous ne pouvez pas compiler tout le corpus et que la question est conversationnelle.
Pour tout le reste, il existe un meilleur outil. Les équipes qui livrent des agents de production en 2026 cesseront de traiter le RAG comme défaut et feront correspondre paradigme et charge de travail.
C’est la barre. Le diagramme rend le choix visible.
Où Copyl s’inscrit
Dans Copyl, les trois paradigmes existent comme primitives natives :
- Récupération conversationnelle s’appuie sur des Knowledge Briefs compilés depuis la KB (Books, Chapters, Docs), avec repli vectoriel pour les questions longue traîne.
- Matrix Agents sont des agents de première classe (stockés avec le même schéma User-and-properties que les agents conversationnels) sur une grille 2D sources × dimensions d’analyse.
- Extraction déterministe est prise en charge via IntegrationApps et accès SQL/API directs, avec résultats disponibles pour les autres paradigmes lorsqu’une interprétation est nécessaire en aval.
Parce que les trois vivent sur la même plateforme, le même Agent Profile, Policies et SOPs s’appliquent à tous les paradigmes — un agent qui fait du Q&A conversationnel un jour et de l’analyse matricielle le lendemain utilise la même configuration de conformité, la même piste d’audit et les mêmes règles d’isolement par locataire.
Le diagramme ci-dessus est la carte. La plateforme permet de passer d’une case à l’autre sans tout reconstruire.