Três paradigmas para ancilar agentes de IA em dados privados — e por que “use RAG” deixa de ser uma resposta completa.
A pergunta que toda a equipa acaba por fazer
Como deve um agente de IA aceder aos seus dados privados?
Durante dois anos a resposta padrão foi “use RAG.” Dividir documentos, incorporá-los, recuperar as melhores correspondências no momento da consulta e colá-los no prompt. Funciona para perguntas pontuais sobre documentos estáticos e continua a ser um ponto de partida razoável para protótipos.
Não é uma resposta completa para agentes de produção.
A decisão real não é RAG ou não-RAG. É uma escolha entre três paradigmas — cada um adequado a uma forma distinta de trabalho. Escolher mal significa pagar por capacidades desnecessárias ou pedir a uma ferramenta que resolva um problema para o qual não foi construída.
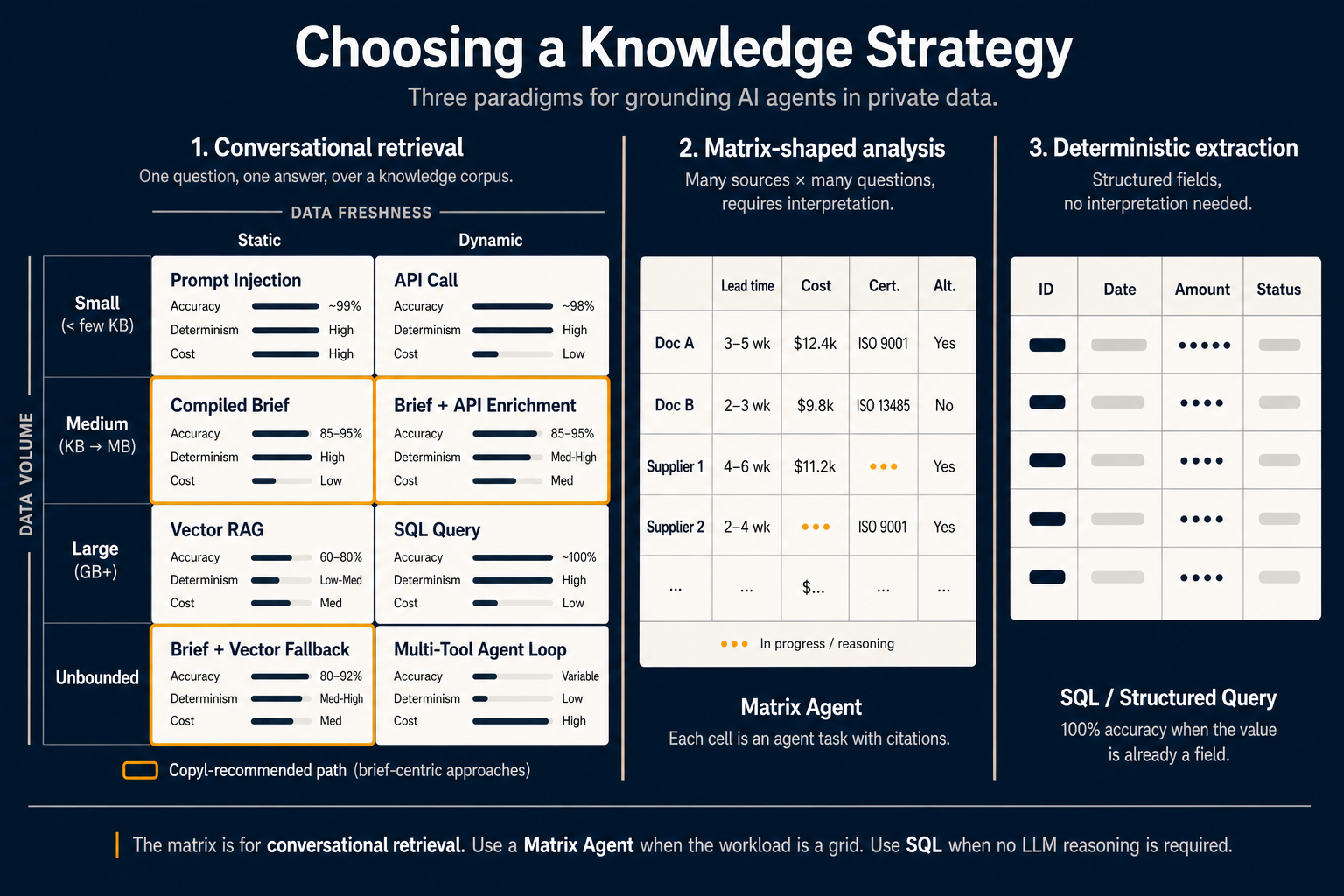
O mapa acima mostra os três.
Paradigma 1 — Recuperação conversacional
Este é o familiar: uma pergunta, uma resposta, ancilada num corpus de conhecimento. A maioria dos agentes baseados em chat vive aqui.
Mas o método de recuperação “certo” depende de duas variáveis que poucas equipas tornam explícitas: quanto dados estão envolvidos e com que frequência mudam.
Trace esses dois eixos e aparecem oito células:
Volume pequeno, dados estáticos — Injeção no prompt. Quando os dados relevantes cabem na janela de contexto do modelo e não mudam no meio da sessão, a resposta mais simples é incluí-los. A precisão aproxima-se dos 99 % porque o modelo não adivinha — vê tudo. O custo: paga esses tokens em cada consulta. Adequado para especificações curtas, caro para o resto.
Volume pequeno, dados dinâmicos — Chamada API. Preço atual de ações, número de tickets abertos, último login. Os dados são pequenos o suficiente para o prompt mas têm de estar frescos. Uma chamada direta à API ou função é a primitiva certa. Não é necessária arquitetura de recuperação.
Volume médio, dados estáticos — Brief compilado. É aqui que a conversa mudou em 2026. Em vez de reinterpretar os mesmos documentos em cada consulta, interpreta-os uma vez em tempo de compilação e guarda o resultado como artefacto optimizado para a tarefa. O agente lê o brief, não os documentos em bruto. Precisão entre 85–95 %, alto determinismo e menor custo por consulta ao enviar resumos destilados em vez de fragmentos crus.
Volume médio, dados dinâmicos — Brief + enriquecimento API. O mesmo enfoque compilado com uma chamada API em tempo real que injecta valores actuais no contexto já pré-interpretado. Adequado para “explique a nossa política de devoluções e diga quantas devoluções processámos hoje.”
Volume grande, dados estáticos — RAG vectorial. O clássico. Quando há gigabytes de documentos estáticos e não pode compilar tudo, recorra à recuperação vectorial. Precisão típica 60–80 %, determinismo baixo a médio (a mesma consulta pode devolver fragmentos diferentes entre execuções) e volta a interpretar texto em bruto no momento da consulta. Útil, mas já não o padrão para a maior parte do trabalho de agentes.
Volume grande, dados dinâmicos — Consulta SQL. Quando os dados são grandes e dinâmicos mas vivem numa base estruturada, escreva a consulta. Não incorpore registos transaccionais. SQL oferece 100 % de precisão — não há passo de interpretação; a resposta é o campo.
Ilimitado, estático — Brief + recurso vectorial. Quando o corpus excede o que razoavelmente compilaria por completo, compile o núcleo de alto tráfego em briefs e deixe a recuperação vectorial para a cauda longa. Precisão entre 80–92 %. O ponto ideal para a maioria dos assistentes de conhecimento em produção.
Ilimitado, dinâmico — Ciclo multi-ferramenta. O caso mais difícil: grande demais para compilar, variado demais para consultar directamente, rápido demais para cachear. O agente tem de planear, chamar várias ferramentas, avaliar resultados intermédios e iterar. Precisão variável, baixo determinismo, alto custo. Apenas quando nada mais simples chega.
As células com contorno laranja marcam o caminho centrado em briefs — células que movem o raciocínio do tempo de consulta para o tempo de compilação. É a configuração que recomendamos por defeito para agentes conversacionais de produção no Copyl.
Paradigma 2 — Análise em forma de matriz
A matriz 2×4 responde bem a uma pergunta. É a ferramenta errada para outra que surge com a mesma frequência: “analise 200 documentos face a 15 dimensões e dê-me uma comparação estruturada.”
Isso não é recuperação conversacional. É outra forma de trabalho.
Um analista de BOM a comparar propostas de fornecedores, uma equipa de M&A a rever 50 contratos face a 20 dimensões de risco, um CFO a rever orçamentos em 12 subsidiárias — fluxos com forma de matriz. As linhas são fontes. As colunas são perguntas. As células são a intersecção: cada célula é uma pequena tarefa de agente que extrai e raciocina sobre essa fonte face a essa pergunta, com citações.
Isto é o que faz um Matrix Agent. A interface é uma folha de cálculo, não um chat. O utilizador adiciona linhas apontando para fontes (documentos, fornecedores, subsidiárias, artigos de KB, registos API) e colunas com um prompt curto que define o que cada célula deve extrair ou avaliar. O agente preenche a grelha em paralelo; cada célula tem a sua própria confiança e citações.
A coluna central do diagrama mostra a prática: documentos e fornecedores como linhas; prazo de entrega, custo, certificação e alternativas como colunas; algumas células preenchidas, outras ainda em resolução. O indicador “em curso” em duas células é relevante — os Matrix Agents são explicitamente por célula; uma célula lenta ou falhada não bloqueia o resto da grelha.
Se alguma vez construiu uma folha única para comparar dados extraídos de muitos documentos, fez à mão o que um Matrix Agent faz em escala.
Paradigma 3 — Extração determinística
O terceiro paradigma é o menos celebrado e o mais fácil de esquecer quando a IA está em todo o lado: não usar um LLM de todo.
Se o valor que precisa já é um campo numa base de dados, numa resposta API estruturada, num CSV ou num JSON bem formado — não precisa de recuperação, nem de brief, nem de Matrix Agent. Precisa de um SELECT.
A extração determinística dá 100 % de precisão, reprodutibilidade perfeita e custo quase nulo por consulta. Só deve escalar para uma abordagem baseada em LLM se os dados não estiverem estruturados ou a pergunta não puder ser respondida combinando campos com lógica simples.
Surpreendentemente, muito do que se constrói como “funcionalidades de IA” devia ser SQL.
Como escolher — versão curta
O rodapé do diagrama resume numa linha — aqui desenvolvido:
- Recuperação conversacional (Paradigma 1) quando o utilizador faz uma pergunta e espera uma resposta em prosa, ancilada no seu corpus privado.
- Matrix Agent (Paradigma 2) quando a carga é uma grelha: muitas fontes face a muitas dimensões e o utilizador quer comparação estruturada em vez de conversa.
- SQL ou consulta estruturada (Paradigma 3) quando o valor já é um campo. Sem interpretação, sem LLM.
Os erros dispendiosos acontecem quando as equipas forçam um paradigma a fazer o trabalho de outro. A recuperação conversacional falha na análise em grelha — o utilizador acaba a executar 200 consultas separadas manualmente. Matrix Agents são excesso para “qual é a nossa política de devoluções” — isso é apenas um brief. Pedir a um LLM para extrair um valor que já é uma coluna é pagar interpretação desnecessária.
Onde fica o debate “RAG ou não”
O RAG vectorial é uma célula no mapa, não o mapa inteiro. É a ferramenta certa para um tipo de problema: grandes volumes de dados estáticos não estruturados quando não pode compilar todo o corpus e a pergunta é conversacional.
Para o resto há uma ferramenta melhor. As equipas que enviam agentes de produção em 2026 deixarão de tratar RAG como padrão e farão corresponder paradigma e carga de trabalho.
Essa é a régua. O diagrama torna a escolha visível.
Onde o Copyl se encaixa
No Copyl, os três paradigmas existem como primitivas nativas:
- Recuperação conversacional corre sobre Knowledge Briefs compilados a partir da KB (Books, Chapters, Docs), com recurso vectorial para perguntas de cauda longa.
- Matrix Agents são agentes de primeira classe (armazenados com o mesmo padrão User-and-properties dos agentes conversacionais) sobre uma grelha 2D de fontes × dimensões de análise.
- Extração determinística é suportada via IntegrationApps e acesso directo SQL/API, com resultados disponíveis para os outros paradigmas quando é necessária interpretação a jusante.
Como os três vivem na mesma plataforma, o mesmo Agent Profile, Policies e SOPs aplicam-se em todos os paradigmas — um agente que faz Q&A conversacional num dia e análise matricial noutro usa a mesma configuração de conformidade, o mesmo rasto de auditoria e as mesmas regras de isolamento por inquilino.
O diagrama acima é o mapa. A plataforma é o que permite mover-se entre células sem reconstruir do zero.