Tres paradigmas para anclar agentes de IA en datos privados — y por qué “usa RAG” ya no es una respuesta completa.
La pregunta que todo equipo acaba haciendo
¿Cómo debe acceder un agente de IA a sus datos privados?
Durante dos años la respuesta por defecto fue “usa RAG.” Fragmentar documentos, incrustarlos, recuperar las mejores coincidencias en tiempo de consulta e insertarlos en el prompt. Funciona para preguntas puntuales sobre documentos estáticos y sigue siendo un punto de partida razonable para prototipos.
No es una respuesta completa para agentes de producción.
La decisión real no es RAG o no RAG. Es una elección entre tres paradigmas — cada uno encaja con una forma distinta de trabajo. Elegir mal significa pagar capacidades que no necesita o pedirle a una herramienta que resuelva un problema para el que no está hecha.
El mapa de arriba muestra los tres.
Paradigma 1 — Recuperación conversacional
Este es el conocido: una pregunta, una respuesta, anclada en un corpus. La mayoría de los agentes basados en chat viven aquí.
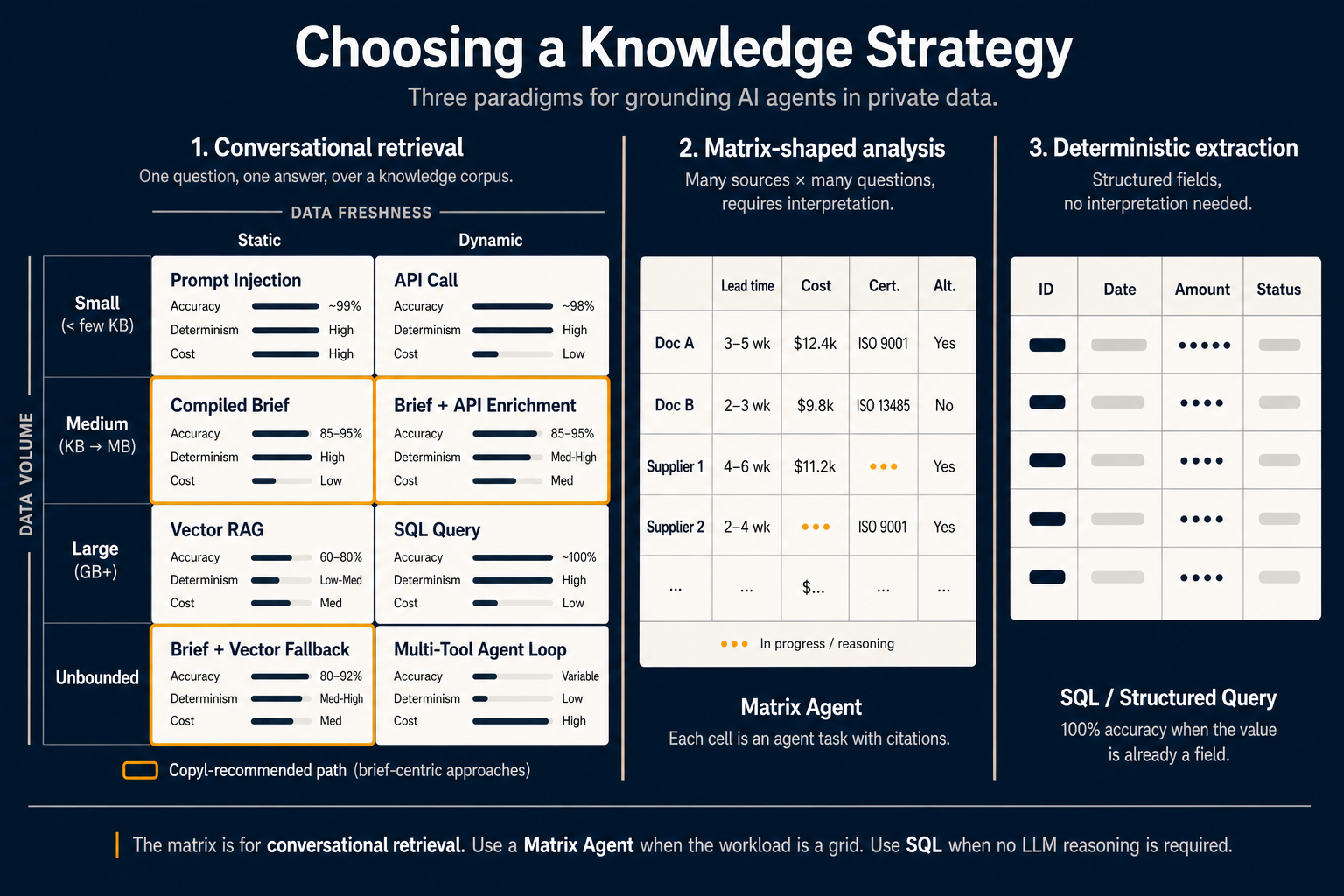
Pero el método de recuperación “correcto” depende de dos variables que pocos equipos explicitan: cuántos datos hay y con qué frecuencia cambian.
Trace esos dos ejes y aparecen ocho celdas:
Volumen pequeño, datos estáticos — Inyección en el prompt. Cuando los datos relevantes caben en la ventana de contexto del modelo y no cambian a mitad de sesión, la respuesta más simple es incluirlos. La precisión se acerca al 99 % porque el modelo no adivina — lo ve todo. El coste: paga esos tokens en cada consulta. Bien para especificaciones cortas, caro para lo demás.
Volumen pequeño, datos dinámicos — Llamada API. Precio de acciones actual, número de tickets abiertos, último inicio de sesión. Los datos son lo bastante pequeños para el prompt pero deben estar frescos. Una llamada directa a API o función es la primitiva adecuada. No hace falta arquitectura de recuperación.
Volumen medio, datos estáticos — Brief compilado. Aquí se ha movido el debate en 2026. En lugar de reinterpretar los mismos documentos en cada consulta, los interpreta una vez en tiempo de compilación y guarda el resultado como artefacto optimizado para la tarea. El agente lee el brief, no los documentos en bruto. Precisión del 85–95 %, alto determinismo y menor coste por consulta al enviar resúmenes destilados en lugar de fragmentos crudos.
Volumen medio, datos dinámicos — Brief + enriquecimiento API. El mismo enfoque compilado con una llamada API en vivo que inyecta valores actuales en el contexto ya preinterpretado. Adecuado para “explica nuestra política de devoluciones y dime cuántas devoluciones procesamos hoy.”
Volumen grande, datos estáticos — RAG vectorial. El clásico. Cuando tiene gigabytes de documentos estáticos y no puede compilarlo todo, recurra a recuperación vectorial. Precisión típica 60–80 %, determinismo bajo o medio (la misma consulta puede devolver fragmentos distintos entre ejecuciones) y vuelve a interpretar texto en bruto en tiempo de consulta. Útil, pero ya no el valor por defecto para la mayoría del trabajo de agentes.
Volumen grande, datos dinámicos — Consulta SQL. Cuando los datos son grandes y dinámicos pero viven en una base estructurada, escriba la consulta. No incruste registros transaccionales. SQL ofrece 100 % de precisión — no hay paso de interpretación; la respuesta es el campo.
Ilimitado, estático — Brief + retorno vectorial. Cuando el corpus supera lo que razonablemente compilaría por completo, compile el núcleo de alto tráfico en briefs y deje la recuperación vectorial para la cola larga. Precisión del 80–92 %. El punto dulce para la mayoría de asistentes de conocimiento en producción.
Ilimitado, dinámico — Bucle multi-herramienta. El caso más duro: demasiado grande para compilar, demasiado variado para consultar directamente, demasiado rápido para cachear. El agente debe planificar, llamar varias herramientas, evaluar resultados intermedios e iterar. Precisión variable, bajo determinismo, alto coste. Solo cuando nada más simple basta.
Las celdas con borde naranja marcan la ruta centrada en briefs — celdas que mueven el razonamiento del tiempo de consulta al tiempo de compilación. Es la configuración que recomendamos por defecto para agentes conversacionales de producción en Copyl.
Paradigma 2 — Análisis en forma de matriz
La matriz 2×4 responde bien a una pregunta. Es la herramienta equivocada para otra que surge con la misma frecuencia: “analiza 200 documentos frente a 15 dimensiones y dame una comparación estructurada.”
Eso no es recuperación conversacional. Es otra forma de trabajo.
Un analista de BOM comparando ofertas de proveedores, un equipo de M&A revisando 50 contratos frente a 20 dimensiones de riesgo, un CFO revisando presupuestos en 12 filiales — flujos con forma de matriz. Las filas son fuentes. Las columnas son preguntas. Las celdas son la intersección: cada celda es una pequeña tarea de agente que extrae y razona sobre esa fuente frente a esa pregunta, con citas.
Esto es lo que hace un Matrix Agent. La interfaz es una hoja de cálculo, no un chat. El usuario añade filas señalando fuentes (documentos, proveedores, filiales, artículos de KB, registros API) y columnas con un prompt breve que define qué debe extraer o evaluar cada celda. El agente rellena la cuadrícula en paralelo; cada celda lleva su propia confianza y citas.
La columna central del diagrama muestra la práctica: documentos y proveedores como filas; plazo de entrega, coste, certificación y alternativas como columnas; algunas celdas completas, otras en curso. El indicador “en curso” en dos celdas importa — los Matrix Agents son explícitamente por celda; una celda lenta o fallida no bloquea el resto de la cuadrícula.
Si alguna vez construyó una hoja única para comparar datos extraídos de muchos documentos, hizo a mano lo que un Matrix Agent hace a escala.
Paradigma 3 — Extracción determinista
El tercer paradigma es el menos celebrado y el más fácil de olvidar cuando la IA está de moda: no usar un LLM en absoluto.
Si el valor que necesita ya es un campo en una base de datos, en una respuesta API estructurada, en un CSV o en JSON bien formado — no necesita recuperación, ni brief, ni Matrix Agent. Necesita un SELECT.
La extracción determinista da 100 % de precisión, reproducibilidad perfecta y coste casi nulo por consulta. Solo debe escalar a un enfoque basado en LLM si los datos no están estructurados o la pregunta no puede responderse combinando campos con lógica simple.
Sorprendentemente, mucho de lo que se construye como “funciones de IA” debería ser SQL.
Cómo elegir — versión breve
El pie del diagrama lo dice en una línea; aquí desarrollado:
- Recuperación conversacional (Paradigma 1) cuando el usuario hace una pregunta y espera una respuesta en prosa, anclada en su corpus privado.
- Matrix Agent (Paradigma 2) cuando la carga es una cuadrícula: muchas fuentes frente a muchas dimensiones y el usuario quiere comparación estructurada en lugar de conversación.
- SQL o consulta estructurada (Paradigma 3) cuando el valor ya es un campo. Sin interpretación, sin LLM.
Los errores caros ocurren cuando los equipos fuerzan un paradigma a hacer el trabajo de otro. La recuperación conversacional lucha con el análisis en cuadrícula — el usuario acaba lanzando 200 consultas separadas. Los Matrix Agents son exceso para “cuál es nuestra política de devoluciones” — eso es solo un brief. Pedir a un LLM que extraiga un valor que ya es una columna es pagar interpretación innecesaria.
Dónde queda el debate “RAG o no”
El RAG vectorial es una celda del mapa, no el mapa completo. Es la herramienta adecuada para un tipo de problema: grandes volúmenes de datos estáticos no estructurados cuando no puede compilar todo el corpus y la pregunta es conversacional.
Para todo lo demás hay una herramienta mejor. Los equipos que despliegan agentes de producción en 2026 dejarán de tratar RAG como predeterminado y emparejarán paradigma y carga de trabajo.
Esa es la vara. El diagrama hace visible la elección.
Dónde encaja Copyl
En Copyl, los tres paradigmas existen como primitivas nativas:
- Recuperación conversacional funciona con Knowledge Briefs compilados desde la KB (Books, Chapters, Docs), con retorno vectorial para preguntas de cola larga.
- Matrix Agents son agentes de primera clase (almacenados con el mismo patrón User-and-properties que los agentes conversacionales) sobre una cuadrícula 2D de fuentes × dimensiones de análisis.
- Extracción determinista está soportada mediante IntegrationApps y acceso directo SQL/API, con resultados disponibles para los otros paradigmas cuando haga falta interpretación aguas abajo.
Como los tres viven en la misma plataforma, el mismo Agent Profile, Policies y SOPs se aplican en todos los paradigmas — un agente que hace Q&A conversacional un día y análisis matricial al siguiente usa la misma configuración de cumplimiento, el mismo rastro de auditoría y las mismas reglas de aislamiento por inquilino.
El diagrama de arriba es el mapa. La plataforma es lo que le permite moverse entre celdas sin reconstruir desde cero.