Drei Paradigmen zur Verankerung von KI-Agenten in privaten Daten — und warum „RAG nutzen“ keine vollständige Antwort mehr ist.
Die Frage, die jedes Team irgendwann stellt
Wie soll ein KI-Agent auf Ihre privaten Daten zugreifen?
Zwei Jahre lang war die Standardantwort: „Nutzen Sie RAG.“ Dokumente chunken, einbetten, zur Abfragezeit die besten Treffer abrufen, in den Prompt einfügen. Das funktioniert für Einzelfragen über statische Dokumente und bleibt ein vernünftiger Startpunkt für Prototypen.
Es ist keine vollständige Antwort für Produktionsagenten.
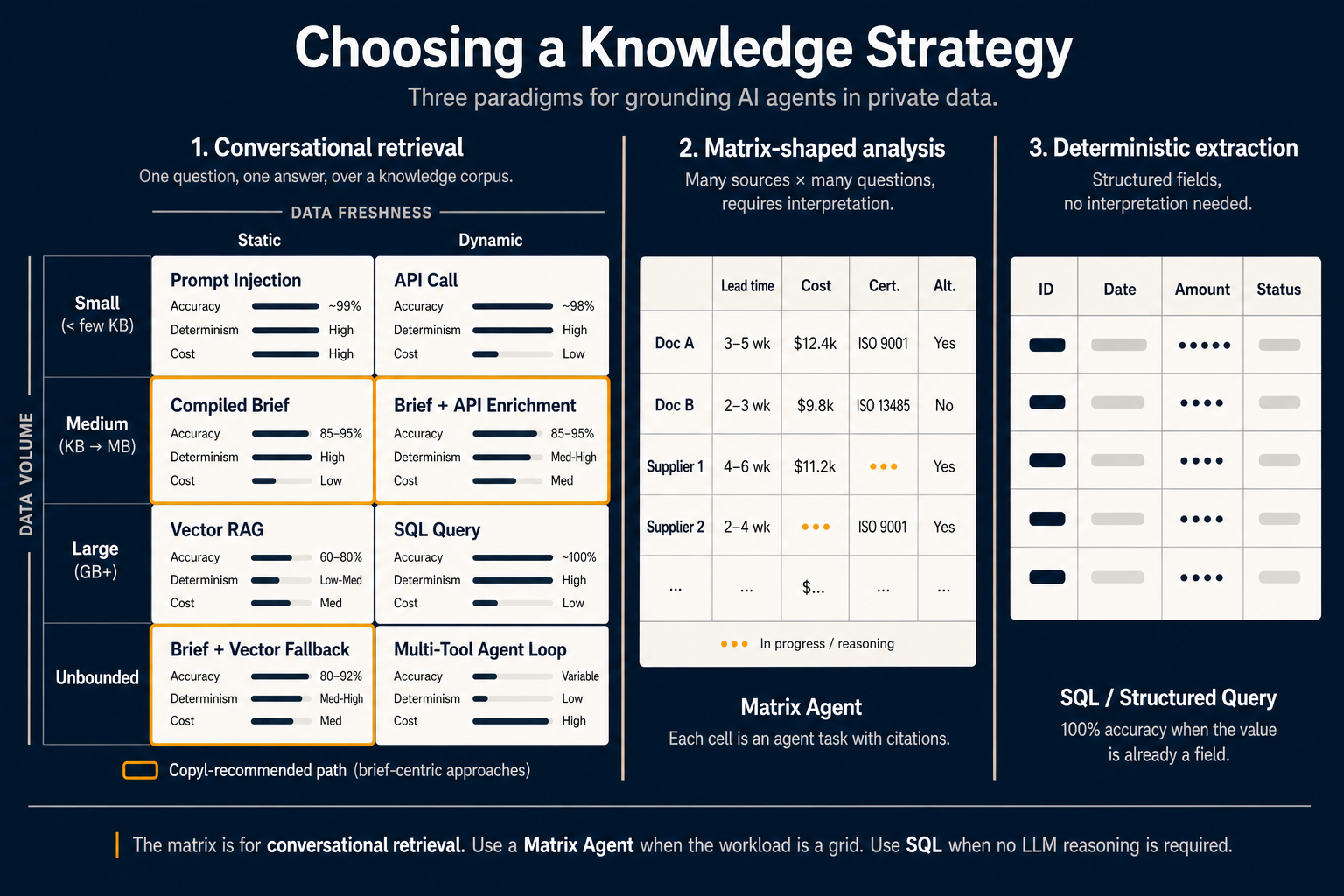
Die eigentliche Entscheidung lautet nicht RAG oder kein RAG. Es ist eine Wahl zwischen drei Paradigmen — jedes passt zu einer anderen Art von Arbeit. Das falsche Paradigma bedeutet: Sie zahlen für Fähigkeiten, die Sie nicht brauchen, oder Sie erwarten von einem Werkzeug, dass es ein Problem löst, für das es nicht gebaut wurde.
Die Karte oben zeigt alle drei.
Paradigma 1 — Konversationelles Retrieval
Das ist das vertraute Muster: eine Frage, eine Antwort, verankert in einem Wissenscorpus. Die meisten Chat-Agenten leben hier.
Innerhalb dieses Paradigmas hängt die „richtige“ Retrieval-Methode aber von zwei Variablen ab, die die wenigsten Teams explizit machen: wie viele Daten betroffen sind und wie oft sich die Daten ändern.
Tragen Sie diese beiden Achsen ein — und acht Zellen entstehen:
Kleines Volumen, statische Daten — Prompt-Injektion. Passt der relevante Kontext ins Kontextfenster des Modells und ändert sich nicht mitten in der Session, ist die einfachste Antwort: alles mitschicken. Die Genauigkeit nähert sich 99 %, weil das Modell nicht raten muss — es sieht alles. Der Haken: Sie zahlen diese Tokens bei jeder Abfrage. Für kurze Spezifikationen okay, für alles andere teuer.
Kleines Volumen, dynamische Daten — API-Aufruf. Aktueller Aktienkurs, Anzahl offener Tickets, letzte Anmeldung. Die Daten sind klein genug für den Prompt, müssen aber frisch sein. Ein direkter API- oder Funktionsaufruf ist das richtige Primitive. Keine Retrieval-Architektur nötig.
Mittleres Volumen, statische Daten — Kompiliertes Briefing. Hier hat sich 2026 die Diskussion verschoben. Statt dieselben Dokumente bei jeder Abfrage neu zu interpretieren, interpretieren Sie einmal zur Compile-Zeit und speichern das Ergebnis als aufgabenoptimiertes Artefakt. Der Agent liest das Briefing, nicht die Rohdokumente. Genauigkeit im Bereich 85–95 %, hohe Determinismus, sinkende Kosten pro Abfrage, weil Sie destillierte Zusammenfassungen statt roher Chunks liefern.
Mittleres Volumen, dynamische Daten — Briefing + API-Anreicherung. Derselbe kompilierte Ansatz, plus ein Live-API-Call, der aktuelle Werte in den ansonsten vorinterpretierten Kontext einspielt. Richtig für Fragen wie: „Erkläre unsere Rückgaberichtlinie und sag mir, wie viele Rücksendungen wir heute bearbeitet haben.“
Großes Volumen, statische Daten — Vector-RAG. Der Klassiker. Haben Sie Gigabytes statischer Dokumente und können nicht alles kompilieren, fallen Sie auf Vektor-Retrieval zurück. Genauigkeit oft 60–80 %, Determinismus niedrig bis mittel (dieselbe Abfrage kann unterschiedliche Chunks liefern), und Sie interpretieren wieder Rohtext zur Abfragezeit. Nützlich — aber nicht mehr der Default für die meisten Agentenaufgaben.
Großes Volumen, dynamische Daten — SQL-Abfrage. Sind die Daten groß und dynamisch, liegen aber strukturiert in einer Datenbank: schreiben Sie die Abfrage. Transaktionsdatensätze nicht einbetten. SQL liefert 100 % Genauigkeit — kein Interpretationsschritt, die Antwort ist das Feld.
Unbegrenzt, statisch — Briefing + Vector-Fallback. Übersteigt der Korpus, was Sie vollständig kompilieren wollen, kompilieren Sie den Kern mit hohem Traffic zu Briefings und lassen Vector-Retrieval den Long Tail abdecken. Genauigkeit etwa 80–92 %. Der Sweet Spot für die meisten Produktions-Assistenzsysteme.
Unbegrenzt, dynamisch — Multi-Tool-Agentenschleife. Der härteste Fall: zu groß zum vollständigen Kompilieren, zu heterogen für direkte Abfragen, zu schnell wechselnd zum Cachen. Der Agent muss planen, mehrere Tools aufrufen, Zwischenergebnisse bewerten und iterieren. Variable Genauigkeit, niedriger Determinismus, hohe Kosten. Nur wenn nichts Einfacheres reicht.
Die orange umrandeten Zellen markieren den briefing-zentrierten Pfad — Zellen, die Reasoning von der Abfragezeit zur Compile-Zeit verschieben. Das empfehlen wir als Standard für konversationelle Produktionsagenten in Copyl.
Paradigma 2 — Matrixförmige Analyse
Die 2×4-Matrix beantwortet eine Frage gut. Für eine andere, ebenso häufige Frage ist sie das falsche Werkzeug: „Analysiere 200 Dokumente gegenüber 15 Dimensionen und liefere einen strukturierten Vergleich.“
Das ist kein konversationelles Retrieval. Es ist eine andere Arbeitsform.
Ein BOM-Analyst, der Lieferantenangebote vergleicht, ein M&A-Team mit 50 Verträgen und 20 Risikodimensionen, ein CFO mit Budgeteinreichungen über 12 Tochtergesellschaften — matrixförmige Workflows. Zeilen sind Quellen. Spalten sind Fragen. Zellen sind die Schnittmenge: jede Zelle ist eine kleine Agentenaufgabe, die diese Quelle gegen diese Frage extrahiert und begründet — mit Zitaten.
Das leistet ein Matrix Agent. Die Oberfläche ist eine Tabelle statt Chat. Zeilen kommen aus Quellen (Dokumente, Lieferanten, Tochtergesellschaften, KB-Artikel, API-Datensätze); Spalten definieren Sie mit kurzen Prompts. Der Agent füllt das Raster parallel; jede Zelle hat eigene Konfidenz und Zitate.
Die mittlere Spalte im Diagramm zeigt die Praxis: Dokumente und Lieferanten als Zeilen; Lieferzeit, Kosten, Zertifizierung, Alternativen als Spalten; einige Zellen gefüllt, andere noch in Arbeit. „In Bearbeitung“ in zwei Zellen ist relevant — Matrix Agents sind explizit pro Zelle; eine langsame oder fehlschlagende Zelle blockiert nicht das gesamte Raster.
Wenn Sie schon einmal ein Einmal-Spreadsheet gebaut haben, um Extrakte aus vielen Dokumenten zu vergleichen, haben Sie manuell gemacht, was ein Matrix Agent skaliert.
Paradigma 3 — Deterministische Extraktion
Das dritte Paradigma ist das am wenigsten gefeierte und am leichtesten zu vergessen, wenn überall „KI“ steht: gar keinen LLM verwenden.
Steht der gewünschte Wert bereits als Feld in einer Datenbank, in einer strukturierten API-Antwort, in einer CSV oder in gut geformtem JSON — brauchen Sie kein Retrieval, kein Briefing, keinen Matrix Agent. Sie brauchen ein SELECT.
Deterministische Extraktion liefert 100 % Genauigkeit, perfekte Reproduzierbarkeit und nahezu keine Kosten pro Abfrage. Ein LLM ist nur nötig, wenn die Daten nicht strukturiert sind oder die Frage nicht durch Kombination strukturierter Felder und einfacher Logik beantwortbar ist.
Überraschend viel von dem, was als „KI-Features“ verkauft wird, sollte SQL sein.
Kurz: wie man wählt
Die Fußzeile des Diagramms fasst es in einem Satz zusammen — hier ausgeschrieben:
- Konversationelles Retrieval (Paradigma 1), wenn der Nutzer eine Frage stellt und eine Antwort in Prosa erwartet, verankert im privaten Corpus.
- Matrix Agent (Paradigma 2), wenn die Arbeit ein Raster ist: viele Quellen gegen viele Dimensionen, strukturierter Vergleich statt Unterhaltung.
- SQL oder strukturierte Abfrage (Paradigma 3), wenn der Wert schon ein Feld ist. Keine Interpretation, kein LLM.
Teure Fehler entstehen, wenn Teams ein Paradigma zum Job eines anderen zwingen. Konversationelles Retrieval scheitert an Rasteranalysen — der Nutzer feuert 200 Einzelabfragen ab. Matrix Agents sind zu viel für „Was sagt unsere Rückgaberichtlinie?“ — das ist ein Briefing. Ein LLM zu bitten, einen Wert zu extrahieren, der schon eine Tabellenspalte ist, bezahlt Interpretation, die nicht nötig war.
Was bleibt von „RAG oder nicht“?
Vector-RAG ist eine Zelle auf der Karte, nicht die ganze Karte. Es passt zu einem Problemtyp: große Mengen statischer, unstrukturierter Daten, bei denen Sie den gesamten Korpus nicht kompilieren können und die Frage konversationell ist.
Für alles andere gibt es ein besser passendes Werkzeug. Teams, die 2026 Produktionsagenten ausliefern, hören auf, RAG als Default zu behandeln, und ordnen Paradigma und Workload einander zu.
Das ist die Messlatte. Das Diagramm macht die Entscheidung sichtbar.
Wo Copyl einzuordnen ist
In Copyl existieren alle drei Paradigmen als native Bausteine:
- Konversationelles Retrieval läuft auf Knowledge Briefs aus der KB (Books, Chapters, Docs) mit Vector-Fallback für Long-Tail-Fragen.
- Matrix Agents sind erstklassige Agenten (gleiches User-and-properties-Muster wie konversationelle Agenten) über ein 2D-Raster Quellen × Analysedimensionen.
- Deterministische Extraktion erfolgt über IntegrationApps und direkten SQL-/API-Zugang; Ergebnisse stehen den anderen Paradigmen zur Verfügung, wenn downstream Interpretation nötig ist.
Weil alle drei auf derselben Plattform leben, gelten dieselbe Agent Profile-, Policies- und SOPs-Konfiguration — ein Agent mit Konversations-Q&A am Montag und Matrixanalyse am Dienstag nutzt dieselbe Compliance-, Audit- und Mandantenisolation.
Das Diagramm ist die Landkarte. Die Plattform ist es, die den Wechsel zwischen Zellen ohne Neubau ermöglicht.