Three paradigms for grounding AI agents in private data — and why “use RAG” is no longer a complete answer.
The question every team eventually asks
How should an AI agent access your private data?
For two years the default answer was “use RAG.” Chunk the documents, embed them, retrieve the top matches at query time, paste them into the prompt. It works for one-off questions over static documents, and it’s still a reasonable starting point for prototypes.
It is not a complete answer for production agents.
The real decision isn’t RAG vs no-RAG. It’s a choice between three different paradigms — each one fitting a different shape of work. Picking the wrong one means paying for capabilities you don’t need, or asking a tool to solve a problem it wasn’t built for.
The map above shows all three.
Paradigm 1 — Conversational retrieval
This is the familiar one: a single question, a single answer, grounded in a knowledge corpus. Most chat-based agents live here.
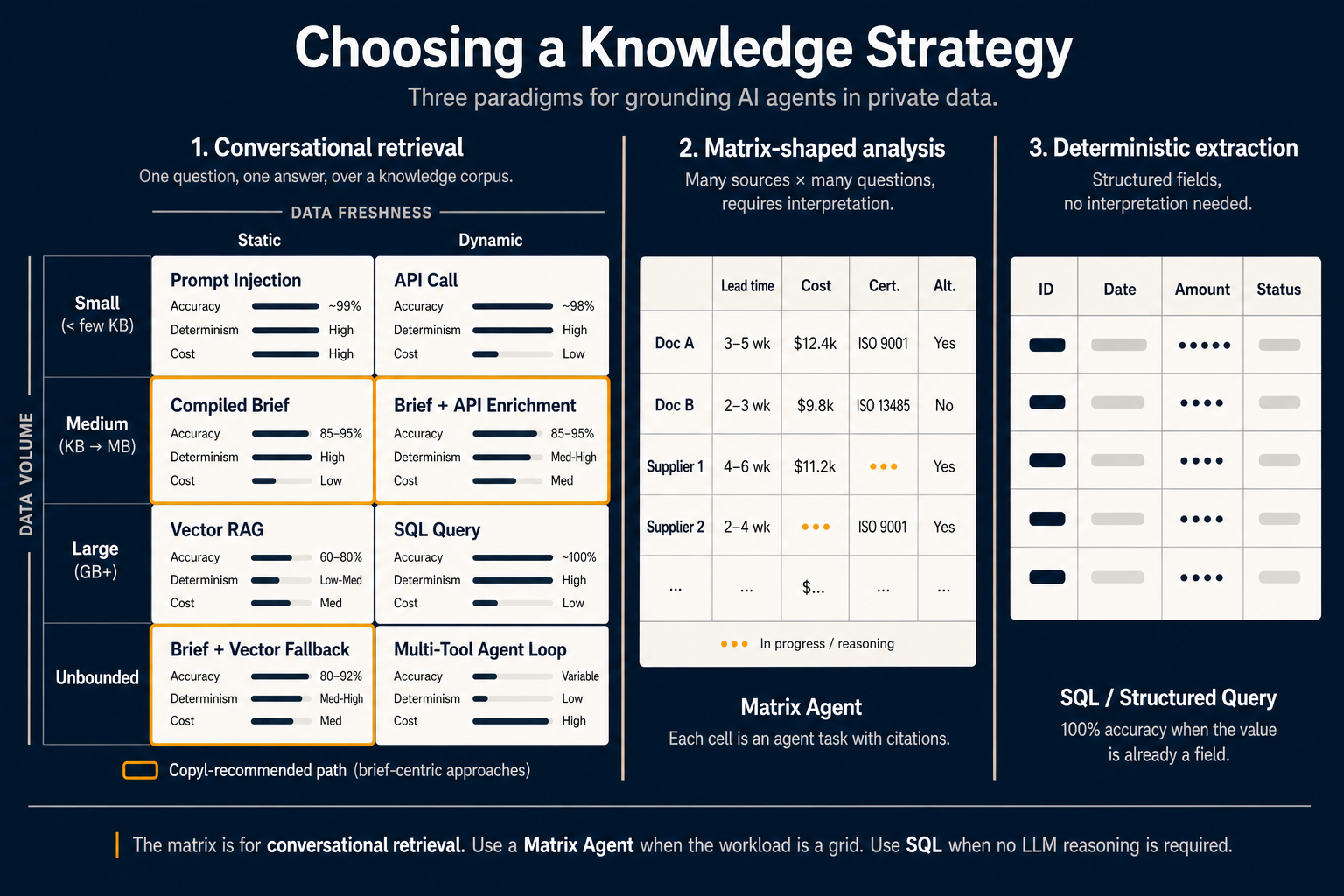
But within this paradigm, the “right” retrieval method depends on two variables most teams never make explicit: how much data is involved, and how often that data changes.
Plot those two axes and eight cells appear:
Small volume, static data — Prompt injection. When the relevant data fits in the model’s context window and never changes mid-session, the simplest answer is to just include it. Accuracy approaches 99% because the model isn’t guessing what’s relevant — it sees everything. The catch: you pay for those tokens on every query. Fine for short specs, expensive for anything else.
Small volume, dynamic data — API call. A current stock price, an open ticket count, a user’s last login. The data is small enough to drop into the prompt, but it has to be fresh. A direct API or function call is the right primitive. No retrieval architecture needed.
Medium volume, static data — Compiled brief. This is where the conversation has shifted in 2026. Instead of re-interpreting the same documents at every query, you interpret them once at compile time and store the result as a task-optimized artifact. The agent reads the brief, not the raw documents. Accuracy stays in the 85–95% range, determinism is high, and per-query cost drops because you’re shipping distilled summaries instead of raw chunks.
Medium volume, dynamic data — Brief + API enrichment. Same compiled brief approach, but with a live API call layered on top to inject current values into the otherwise pre-interpreted context. Right tool for things like “explain our return policy and tell me how many returns we processed today.”
Large volume, static data — Vector RAG. The classic. When you have gigabytes of static documents and you can’t afford to compile all of it, fall back to vector retrieval. Accuracy lives in the 60–80% range, determinism is low to medium (the same query can retrieve different chunks across runs), and you’re back to interpreting raw text at query time. Useful, but not where most agent work should default to anymore.
Large volume, dynamic data — SQL query. When the data is large and dynamic, but it lives in a structured database, just write the query. Don’t embed transactional records. SQL gives 100% accuracy because there’s no interpretation step — the answer is the field.
Unbounded, static data — Brief + vector fallback. When the corpus exceeds what you’d want to compile fully, compile the high-traffic core into briefs and let vector retrieval handle the long tail. Accuracy in the 80–92% range. This is the sweet spot for most production knowledge assistants.
Unbounded, dynamic data — Multi-tool agent loop. The hardest case: the data is too big to compile, too varied to query directly, and changes too fast to cache. The agent has to plan, call multiple tools, evaluate intermediate results, and iterate. Accuracy is variable, determinism is low, and cost is high. Reach for this only when nothing simpler will do.
The orange-bordered cells in the diagram mark the brief-centric path — the cells that move reasoning from query time to compile time. That’s the configuration we recommend by default for production conversational agents in Copyl.
Paradigm 2 — Matrix-shaped analysis
The 2×4 matrix above answers one question well. It is the wrong tool for a different question that comes up just as often: “analyze 200 documents against 15 dimensions and give me a structured comparison.”
That isn’t conversational retrieval. It’s a different shape of work.
A BOM analyst comparing supplier offers, an M&A team reviewing 50 contracts against 20 risk dimensions, a CFO reviewing budget submissions across 12 subsidiaries — these workflows are matrix-shaped. Rows are sources. Columns are questions. Cells are the intersection: each cell is a small agent task that extracts and reasons about that source against that question, with citations.
This is what a Matrix Agent does. The interface is a spreadsheet rather than a chat. The user adds rows by pointing at sources (documents, suppliers, subsidiaries, KB articles, API records) and adds columns by writing a small prompt that defines what each cell should extract or evaluate. The agent fills the grid in parallel, with each cell carrying its own confidence score and citations.
The middle column of the diagram shows what this looks like in practice: documents and suppliers as rows; lead time, cost, certification, and alternatives as columns; some cells already filled, some still resolving. The “in progress” indicator in two cells is meaningful — Matrix Agents are explicitly per-cell, which means a single failing or slow cell doesn’t block the rest of the grid.
If you’ve ever built a one-off spreadsheet to compare extracted data from many documents, you’ve done by hand what a Matrix Agent does at scale.
Paradigm 3 — Deterministic extraction
The third paradigm in the diagram is the most under-celebrated, and the easiest to forget when AI is in the picture: don’t use an LLM at all.
If the value you want is already a field in a database, in a structured API response, in a CSV, or in a well-formed JSON document — you don’t need retrieval, you don’t need a brief, you don’t need a Matrix Agent. You need a SELECT.
Deterministic extraction gives you 100% accuracy, perfect reproducibility, and near-zero per-query cost. The only reason to escalate to an LLM-based approach is if the data isn’t already structured, or the question can’t be answered by combining structured fields with simple logic.
A surprising amount of what gets built as “AI features” should be SQL.
How to pick — the short version
The footer of the diagram says it in one line, but it’s worth spelling out:
- Conversational retrieval (Paradigm 1) when a user is asking a question and expects an answer in prose, with the answer grounded in your private corpus.
- Matrix Agent (Paradigm 2) when the workload is a grid: many sources analyzed against many dimensions, with the user wanting a structured comparison rather than a conversation.
- SQL or structured query (Paradigm 3) when the value is already a field. No interpretation needed, no LLM needed.
The expensive mistakes happen when teams force one paradigm to do another paradigm’s job. Conversational retrieval struggles with grid analysis — the user ends up running 200 separate queries by hand. Matrix Agents are overkill for “what’s our return policy” — that’s just a brief. And asking an LLM to extract a value that’s already a column in a table is paying for interpretation that wasn’t required.
Where this leaves the “RAG vs not” debate
Vector RAG is one cell in this map, not the whole map. It’s the right tool for one specific shape of problem: large volumes of static, unstructured data where you can’t compile the whole corpus and the question is conversational.
For everything else, there’s a better-fitting tool. The teams shipping production agents through 2026 will be the ones who stop treating RAG as a default and start matching paradigm to workload.
That’s the bar. The diagram is one way of making the choice visible.
Where Copyl fits
In Copyl, all three paradigms exist as native primitives:
- Conversational retrieval runs on Knowledge Briefs compiled from the KB (Books, Chapters, Docs), with vector fallback for long-tail questions.
- Matrix Agents are first-class agents (stored using the same User-and-properties pattern as conversational agents) that operate over a 2D grid of sources × analysis dimensions.
- Deterministic extraction is supported through IntegrationApps and direct SQL/API access, with results made available to either of the other two paradigms when interpretation is needed downstream.
Because all three live on the same platform, the same Agent Profile, Policies, and SOPs apply across paradigms — which means an agent that does conversational Q&A on Monday and matrix analysis on Tuesday is using the same compliance configuration, the same audit trail, and the same tenant isolation rules.
The diagram above is the map. The platform is what lets you actually move between cells without rebuilding from scratch.