Kolme paradigmia AI-agenttien ankkurointiin yksityiseen dataan — ja miksi ”käytä RAGia” ei enää ole täydellinen vastaus.
Kysymys, jonka jokainen tiimi ennen pitkää esittää
Miten AI-agentin pitäisi käyttää yksityistänne dataa?
Kaksi vuotta oletusvastaus oli ”käytä RAGia.” Jaa dokumentit paloihin, upota ne, nouda parhaat osumat kyselyhetkellä, liitä promptiin. Toimii kertaluonteisiin kysymyksiin staattisten dokumenttien yli ja on yhä järkevä lähtökohta prototyypeille.
Se ei riitä tuotantoagenteille.
Varsinainen ratkaisu ei ole RAG vai ei-RAG. Kolmen paradigmisen vaihtoehdon välinen valinta — kukin sopii erilaiseen työhön. Väärä valinta tarkoittaa maksua kyvyistä joita ei tarvita tai työkalua väärään tehtävään.
Yllä oleva kartta näyttää kaikki kolme.
Paradigma 1 — Keskusteluhaku
Tämä on tuttu: yksi kysymys, yksi vastaus, ankkuroitu tietopohjaan. Useimmat chat-pohjaiset agentit elävät täällä.
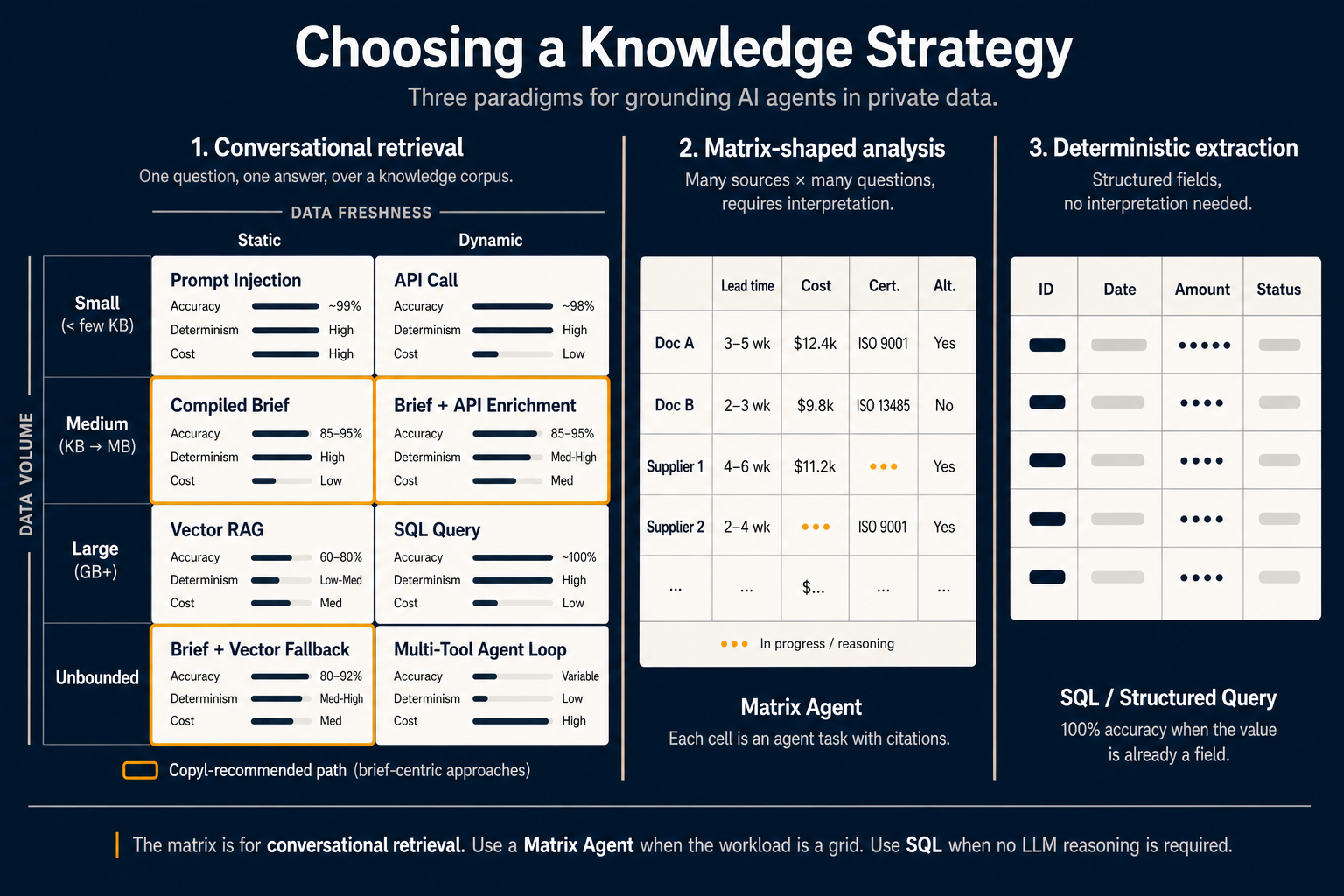
Mutta ”oikea” hakutapa riippuu kahdesta muuttujasta, joita tiimit harvoin tekevät eksplisiittisiksi: kuinka paljon dataa on, ja kuinka usein data muuttuu.
Piirrä nuo akselit — ja kahdeksan ruutua syntyy:
Pieni määrä, staattinen data — Prompt-injektio. Kun relevantti data mahtuu mallin konteksti-ikkunaan eikä muutu istunnon aikana, yksinkertaisin vastaus on sisällyttää se kokonaan. Tarkkuus lähestyy 99 %, koska malli ei arvaile — se näkee kaiken. Hintana tokenit joka kyselyllä. Lyhyisiin spekseihin sopiva, muuten kallista.
Pieni määrä, dynaaminen data — API-kutsu. Nykyinen kurssi, avointen tikettien määrä, käyttäjän viime kirjautuminen. Data on tarpeeksi pieni promptiin mutta pitää olla tuoretta. Suora API- tai funktiokutsu on oikea primitiivi. Ei tarvita hakuarkkitehtuuria.
Keskikokoinen määrä, staattinen data — Käännetty tiivistelmä (compiled brief). Tässä keskustelu on vuonna 2026 siirtynyt. Sen sijaan että tulkitset samoja dokumentteja joka kyselyllä, tulkkaat kerran käännöshetkellä ja tallennat tuloksen tehtävään optimoituna artefaktina. Agentti lukee tiivistelmää, ei raakatekstiä. Tarkkuus 85–95 %, korkea determinismi, alempi kyselykohtainen kustannus koska lähetät tiivistetyt yhteenvedot raakapalojen sijaan.
Keskikokoinen määrä, dynaaminen data — Tiivistelmä + API-rikastus. Sama käännetty lähestymistapa ja live-API injektoi ajantasaiset arvot muuten valmiiksi tulkittuun kontekstiin. Sopii esimerkiksi: ”selitä palautuskäytäntömme ja kerro montako palautusta käsittelimme tänään.”
Suuri määrä, staattinen data — Vektori-RAG. Klassikko. Kun staattisia dokumentteja on gigatavuittain etkä voi kääntää kaikkea, turvaudu vektorihakuun. Tarkkuus tyypillisesti 60–80 %, determinismi matala tai keskitaso (sama kysely voi palauttaa eri paloja eri ajoissa), ja palaat raakatekstin tulkintaan kyselyhetkellä. Hyödyllinen — mutta ei enää oletus useimmille agenttitehtäville.
Suuri määrä, dynaaminen data — SQL-kysely. Kun data on suuri ja dynaaminen mutta rakenteisessa tietokannassa: kirjoita kysely. Älä upota transaktiorivejä. SQL antaa 100 % tarkkuuden — ei tulkintaa, vastaus on kenttä.
Rajoittamaton, staattinen — Tiivistelmä + vektorivaroitus. Kun korpus on laajempi kuin mitä kannattaa kääntää kokonaan: käänä korkean liikenteen ydin tiivistelmiksi ja anna vektorihaulle pitkä häntä. Tarkkuus 80–92 %. Tuotannon tietoavustimien sweet spot.
Rajoittamaton, dynaaminen — Monityökalu-agenttisilmukka. Vaikein tapaus: liian suuri käännettäväksi, liian vaihteleva suoraan kysyttäväksi, liian nopeasti muuttuva välimuistiin. Agentin täytyy suunnitella, kutsua useita työkaluja, arvioida välituloksia ja iteroida. Muuttuva tarkkuus, matala determinismi, korkea kustannus. Vain kun mikään yksinkertaisempi ei riitä.
Oranssireunaiset ruudut merkitsevät tiivistelmäkeskeistä polkua — ruutuja jotka siirtävät päättelyn kyselyhetkestä käännöshetkeen. Suosittelemme oletuksena tuotannon keskusteluagenteille Copylissa.
Paradigma 2 — Matriisimuotoinen analyysi
Yllä oleva 2×4-matriisi vastaa yhteen kysymykseen hyvin. Se on väärä työkalu toiseen yhtä usein esiintyvään: ”analysoi 200 dokumenttia 15 ulottuvuutta vasten ja anna strukturoitu vertailu.”
Se ei ole keskusteluhaku. Se on eri työn muoto.
BOM-analyytikko vertailee toimittajatarjouksia, M&A-tiimi lukee 50 sopimusta 20 riskiulottuvuutta vasten, CFO käy läpi budjetteja 12 tytäryhtiössä — matriisimaisia työnkulkuja. Rivit ovat lähteitä. Sarakkeet ovat kysymyksiä. Solu on leikkaus: jokainen solu on pieni agenttitehtävä joka poimii ja perustelee kyseisen lähteen kyseiseen kysymykseen viittein.
Tämän tekee Matrix Agent. Käyttöliittymä on laskentataulukko chatin sijaan. Käyttäjä lisää rivejä osoittamalla lähteitä (dokumentit, toimittajat, tytäryhtiöt, KB-artikkelit, API-tietueet) ja sarakkeita lyhyillä prompteilla. Agentti täyttää ruudukon rinnakkain; jokaisella solulla on oma luottamus ja viitteet.
Diagrammin keskisarake näyttää käytännön: dokumentit ja toimittajat riveinä; toimitusaika, kustannus, sertifiointi ja vaihtoehdot sarakkeina; osa soluista täytetty, osa vielä käynnissä. ”Käynnissä” kahdessa solussa on merkityksellinen — Matrix Agentit ovat eksplisiittisesti solukohtaisia, joten yksi hidas tai epäonnistunut solu ei estä koko ruudukkoa.
Jos olet koskaan rakentanut kertaluonteisen taulukon vertaillaksesi poimintoja monista dokumenteista, olet tehnyt käsin sen mitä Matrix Agent tekee mittakaavassa.
Paradigma 3 — Deterministinen poiminta
Kolmas paradigma on vähäarvostetuin ja helpoin unohtaa kun AI on kaikkialla: älä käytä LLM:ää ollenkaan.
Jos haluttu arvo on jo kenttänä tietokannassa, strukturoidussa API-vastauksessa, CSV:ssä tai hyvin muodostetussa JSONissa — et tarvitse hakua, tiivistelmää etkä Matrix Agentia. Tarvitset SELECT-kyselyn.
Deterministinen poiminta antaa 100 % tarkkuuden, täydellisen toistettavuuden ja lähes nolla kustannuksen per kysely. LLM-tasolle noustaan vain jos data ei ole strukturoitua tai kysymystä ei voi ratkaista yhdistämällä kenttiä ja yksinkertaista logiikkaa.
Yllättävän paljon ”AI-ominaisuuksiksi” rakennettua pitäisi olla SQL.
Valinta lyhyesti — alatunnisteen laajennus
Diagrammin alatunniste tiivistää yhteen riviin — tässä avattuna:
- Keskusteluhaku (Paradigma 1) kun käyttäjä kysyy ja odottaa vastausta proosassa, ankkuroituna yksityiseen korpusseen.
- Matrix Agent (Paradigma 2) kun työmäärä on ruudukko: monta lähdettä ja ulottuvuutta, käyttäjä haluaa strukturoidun vertailun keskustelun sijaan.
- SQL tai strukturoitu kysely (Paradigma 3) kun arvo on jo kenttä. Ei tulkintaa, ei LLM:ää.
Kalliit virheet syntyvät kun tiimit pakottavat paradigman tekemään toisen työn. Keskusteluhaku kamppailee ruudukkoanalyysin kanssa — käyttäjä ajaa 200 erillistä kyselyä käsin. Matrix Agent on liikaa kysymykseen ”mikä on palautuskäytäntömme” — se on vain tiivistelmä. LLM:n pyytäminen poimimaan arvo joka on jo sarakkeessa maksaa tulkinnasta jota ei tarvittu.
Mihin ”RAG vai ei” -keskustelu jää
Vektori-RAG on yksi ruutu kartalla, ei koko kartta. Se sopii tiettyyn ongelmaan: suuret määrät staattista strukturoimatonta dataa joita ei voi kääntää kokonaan ja kysymys on keskustelullinen.
Muuhun on parempi työkalu. Vuonna 2026 tuotantoagentteja toimittavat tiimit lopettavat RAGin oletuksena ja sovittavat paradigman työmäärään.
Se on rimaa. Diagrammi tekee valinnasta näkyvän.
Missä Copyl sijoittuu
Copylissa kaikki kolme paradigmia ovat natiiveja primitiivejä:
- Keskusteluhaku Knowledge Briefseillä jotka käännetään KB:stä (Books, Chapters, Docs), vektorivaroituksella pitkän hännän kysymyksiin.
- Matrix Agentit ovat ensiluokan agentteja (sama User-and-properties-kuvio kuin keskusteluagenteilla) 2D-ruudukossa lähteet × analyysiulottuvuudet.
- Deterministinen poiminta IntegrationAppsien ja suoran SQL/API-pääsyn kautta; tulokset ovat saatavilla muille paradigmoille jos tulkintaa tarvitaan alavirtaan.
Koska kaikki kolme ovat samalla alustalla, sama Agent Profile, Policies ja SOPs koskevat kaikkia — agentti joka tekee keskustelu-Q&A:ta maanantaina ja matriisi-analyysiä tiistaina käyttää samaa compliance-asetusta, samaa audit-jälkeä ja samaa vuokralaiseristystä.
Yllä oleva diagrammi on kartta. Alusta on se mikä mahdollistaa siirtymisen solujen välillä rakentamatta uudelleen tyhjästä.