Tre paradigm för att förankra AI-agenter i privat data — och varför ”använd RAG” inte längre är ett komplett svar.
Frågan varje team förr eller senare ställer
Hur ska en AI-agent få åtkomst till er privata data?
I två år var standardsvaret ”använd RAG.” Dela dokument i stycken, bädda in dem, hämta de bästa träffarna vid frågetid, klistra in dem i prompten. Det fungerar för engångsfrågor över statiska dokument och är fortfarande en rimlig utgångspunkt för prototyper.
Det är inte ett komplett svar för produktionsagenter.
Den verkliga frågan är inte RAG eller inte RAG. Det är ett val mellan tre paradigm — var och en lämpar sig för en annan typ av arbete. Fel val innebär att ni betalar för förmågor ni inte behöver, eller ber ett verktyg lösa ett problem det inte är byggt för.
Kartan ovan visar alla tre.
Paradigm 1 — Konversationshämtning
Det här är det välbekanta: en fråga, ett svar, förankrat i ett kunskapsunderlag. De flesta chattbaserade agenterna lever här.
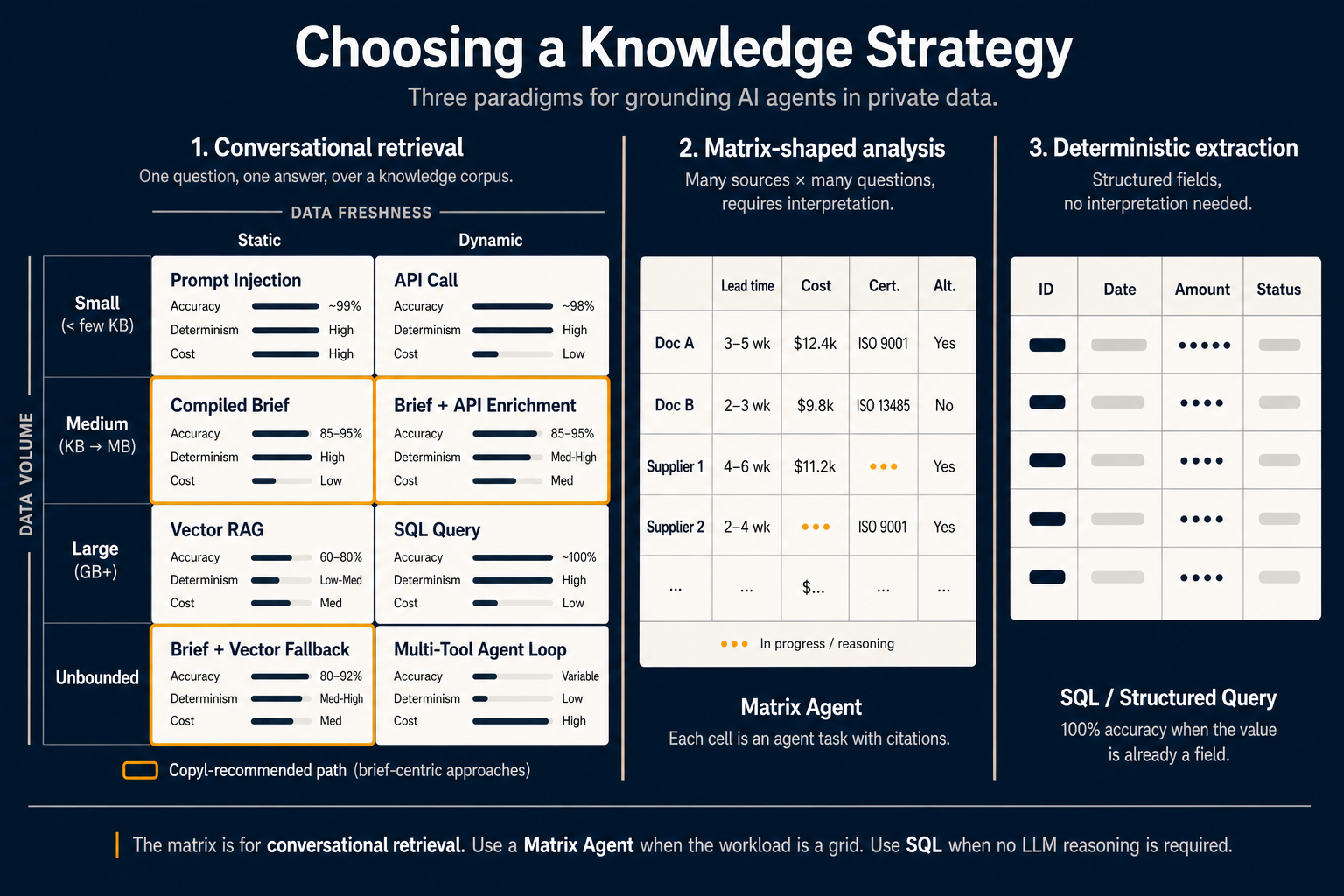
Men inom detta paradigm beror ”rätt” hämtningsmetod på två variabler som de flesta team aldrig gör explicita: hur mycket data det handlar om, och hur ofta data ändras.
Rita in de två axlarna och åtta celler uppstår:
Liten volym, statisk data — Promptinjektion. När relevant data ryms i modellens kontextfönster och inte ändras under sessionen är det enklaste svaret att bara inkludera den. Träffsäkerheten närmar sig 99 % eftersom modellen inte gissar vad som är relevant — den ser allt. Priset: ni betalar tokens vid varje fråga. Bra för korta specar, dyrt för allt annat.
Liten volym, dynamisk data — API-anrop. Ett aktuellt aktiekurs, antal öppna ärenden, användarens senaste inloggning. Datat är tillräckligt litet för prompten men måste vara färskt. Ett direkt API eller funktionsanrop är rätt primitive. Ingen retrieverarkitektur behövs.
Medel volym, statisk data — Kompilerad brief. Här har samtalet flyttat sig 2026. I stället för att tolka om samma dokument vid varje fråga tolkar ni en gång vid kompileringstid och lagrar resultatet som en uppgiftsoptimerad artefakt. Agenten läser briefen, inte rådokumenten. Träffsäkerhet i intervallet 85–95 %, hög determinism, lägre kostnad per fråga eftersom ni skickar destillerade sammanfattningar i stället för råa stycken.
Medel volym, dynamisk data — Brief + API-berikning. Samma kompilerade brief, men med ett live-API ovanpå som injicerar aktuella värden i den i övrigt förinterpretade kontexten. Rätt verktyg när ni vill ”förklara vår returpolicy och säga hur många returer vi hanterat idag.”
Stor volym, statisk data — Vektor-RAG. Klassikern. När ni har gigabyte av statiska dokument och inte kan kompilera allt, fall tillbaka på vektorhämtning. Träffsäkerhet 60–80 %, determinism låg till medel (samma fråga kan ge olika stycken mellan körningar), och ni är tillbaka vid att tolka råtext vid frågetid. Användbart, men inte längre standardvalet för de flesta agentuppgifter.
Stor volym, dynamisk data — SQL-fråga. När datat är stort och dynamiskt men ligger i en strukturerad databas: skriv frågan. Bädda inte in transaktionsrader. SQL ger 100 % träffsäkerhet eftersom det inte finns något tolkningssteg — svaret är fältet.
Obegränsad statisk data — Brief + vektorreserv. När korpusen är större än vad ni rimligen kan kompilera fullt ut: kompilera kärnan med hög trafik till briefs och låt vektorhämtning ta långsvansen. Träffsäkerhet 80–92 %. Det är sweet spot för de flesta produktionsassistenter.
Obegränsad dynamisk data — Multi-verktygs-agentloop. Det svåraste fallet: för stort att kompilera, för varierat att fråga direkt, för snabbt förändrande för cache. Agenten måste planera, anropa flera verktyg, utvärdera mellanresultat och iterera. Träffsäkerhet varierande, låg determinism, hög kostnad. Använd bara när inget enklare räcker.
De orangeinramade cellerna i diagrammet markerar brief-centrerade vägen — cellerna som flyttar resonemang från frågetid till kompileringstid. Det är den konfiguration vi rekommenderar som standard för konversationsagenter i produktion i Copyl.
Paradigm 2 — Matrisformad analys
Matrisen 2×4 ovan svarar bra på en fråga. Den är fel verktyg för en annan som dyker upp lika ofta: ”analysera 200 dokument mot 15 dimensioner och ge mig en strukturerad jämförelse.”
Det är inte konversationshämtning. Det är en annan arbetsform.
En BOM-analytiker som jämför leverantörsbud, ett M&A-team som granskar 50 avtal mot 20 riskdimensioner, en CFO som går igenom budgetunderlag för 12 dotterbolag — matrisformade flöden. Rader är källor. Kolumner är frågor. Celler är skärningspunkten: varje cell är en liten agentuppgift som extraherar och resonerar om källan mot frågan, med citeringar.
Det är vad en Matrix Agent gör. Gränssnittet är ett kalkylblad i stället för en chatt. Användaren lägger till rader genom att peka på källor (dokument, leverantörer, dotterbolag, KB-artiklar, API-poster) och kolumner genom att skriva en kort prompt som definierar vad cellen ska extrahera eller utvärdera. Agenten fyller rutnätet parallellt, med egen konfidens och citeringar per cell.
Mittenkolumnen i diagrammet visar hur det ser ut i praktiken: dokument och leverantörer som rader; ledtid, kostnad, certifiering och alternativ som kolumner; vissa celler ifyllda, andra fortfarande på gå. Indikatorn ”pågår” i två celler är meningsfull — Matrix Agents är uttryckligen per-cell, så en långsam eller misslyckad cell blockerar inte resten av rutnätet.
Har ni någonsin byggt ett engångskalkylblad för att jämföra utdrag från många dokument har ni gjort för hand vad en Matrix Agent gör i skala.
Paradigm 3 — Deterministisk extraktion
Det tredje paradigmet i diagrammet är det mest underskattade och det lättaste att glömma när AI är i bilden: använd inte en LLM alls.
Om värdet ni vill ha redan finns som fält i en databas, i ett strukturerat API-svar, i en CSV eller i välformad JSON — ni behöver varken hämtning, brief eller Matrix Agent. Ni behöver ett SELECT.
Deterministisk extraktion ger 100 % träffsäkerhet, perfekt reproducerbarhet och nästan noll kostnad per fråga. Ni eskalerar till LLM-baserat först när datat inte redan är strukturerat, eller när frågan inte kan besvaras genom att kombinera strukturerade fält med enkel logik.
Överraskande mycket av det som byggs som ”AI-funktioner” borde vara SQL.
Hur ni väljer — kort version
Sidfoten i diagrammet säger det på en rad, men det är värt att stava ut det:
- Konversationshämtning (Paradigm 1) när användaren ställer en fråga och förväntar sig ett svar i löpande text, förankrat i ert privata underlag.
- Matrix Agent (Paradigm 2) när arbetslasten är ett rutnät: många källor mot många dimensioner och användaren vill ha en strukturerad jämförelse i stället för en konversation.
- SQL eller strukturerad fråga (Paradigm 3) när värdet redan är ett fält. Ingen tolkning behövs, ingen LLM behövs.
De dyra misstagen sker när team tvingar ett paradigm att göra ett annats jobb. Konversationshämtning kämpar med rutnätsanalys — användaren kör 200 separata frågor för hand. Matrix Agents är overkill för ”vad säger vår returpolicy” — det är bara en brief. Att be en LLM extrahera ett värde som redan är en kolumn är att betala för tolkning som inte behövdes.
Var det lämnar ”RAG eller inte”-debatten
Vektor-RAG är en cell på kartan, inte hela kartan. Det är rätt verktyg för ett specifikt problem: stora volymer statisk ostrukturerad data där ni inte kan kompilera hela korpusen och frågan är konversationsbaserad.
För allt annat finns ett bättre passande verktyg. De team som levererar produktionsagenter genom 2026 är de som slutar behandla RAG som standard och börjar matcha paradigm till arbetslast.
Det är ribban. Diagrammet är ett sätt att göra valet synligt.
Var Copyl passar in
I Copyl finns alla tre paradigm som inbyggda primitiver:
- Konversationshämtning körs på Knowledge Briefs kompilerade från KB (Books, Chapters, Docs), med vektorreserv för långsvansfrågor.
- Matrix Agents är förstaklassagenter (lagrade med samma User-and-properties-mönster som konversationsagenter) som arbetar över ett 2D-rutnät av källor × analysedimensioner.
- Deterministisk extraktion stöds via IntegrationApps och direkt SQL/API-åtkomst, med resultat tillgängliga för de andra paradigmen när tolkning behövs nedströms.
Eftersom alla tre lever på samma plattform gäller samma Agent Profile, Policies och SOPs över paradigm — en agent som gör konversations-Q&A på måndag och matrisanalys på tisdag använder samma efterlevnadsinställning, samma revisionsspår och samma tenant-isolering.
Diagrammet ovan är kartan. Plattformen är det som låter er faktiskt röra er mellan celler utan att bygga om från grunden.